November 2003, Issue 96 Published by Linux Journal
Front Page | Back Issues | FAQ | MirrorsThe Answer Gang knowledge base (your Linux questions here!)
Search (www.linuxgazette.com)

![[tm]](../gx/tm.gif) ,
http://www.linuxgazette.com/
,
http://www.linuxgazette.com/
|
...making Linux just a little more fun! |
By Javier Malonda |
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site tha t supports, es.comp.os.linux, the Spanish USENET newsgroup for Linux. The strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling. To see a panel in all its clarity, click on it.
![[cartoon]](misc/ecol/ecol-132-e-as.png)
![[cartoon]](misc/ecol/ecol-131-e-as.png)
![[cartoon]](misc/ecol/ecol-129-e-as.png)
![[cartoon]](misc/ecol/ecol-128-e-as.png)
All Ecol cartoons are at tira.escomposlinux.org (Spanish), comic.escomposlinux.org (English) and http://tira.puntbarra.com/ (Catalan). The Catalan version is translated by the people who run the site; only a few episodes are currently available.
These cartoons are copyright Javier Malonda. They may be copied, linked or distributed by any means. However, you may not distribute modifications. If you link to a cartoon, please notify Javier, who would appreciate hearing from you.
|
...making Linux just a little more fun! |
By Phil Hughes |
In late September I wrote an article about radio station automation for the Linux Journal web site. You can find the article The comments I received indicates that there is interest. What I would like to do here is to see if there are some people who would actually be interested in working on such a project. I have establesed a palce on the LG Projects Wiki to further develop this work.
The comments the article received indicated that many of the pieces were in place. Most I knew about and this didn't surprise me. However, I want to build a solution rather than present a shopping list. That solution has to include various pieces of software, all playing together along with support. The pieces I see are:
You can look at this potential customer base in three ways:
The market is huge and very diverse. As a result of that diversity there are lots of choices of where you would like to fit into this project. For example, if you have a political ax to grind, helping your favorite political or religious cause get a radio voice or build a more efficient radio voice is likely your place. If, however, you just want to be in it for the money, there are tens of thousands of radio stations that could use your help and would pay for it.
Just looking at FM broadcast stations, there are 100 available frequencies on the band. In the US, these frequencies are allocated based on the signal strength of other stations on the same and adjacent frequencies. I don't have the numbers handy but that easily means thousands of stations in the US alone. Toss in AM broadcast and shortwave stations and you have the potential customer base for a product. If that isn't enough, Internet-only stations could use the same system.
Hopefully, if you are still reading, this is starting to make sense. I willdescribe the overall project idea and then talk about the specifics from above.
Let me present how a traditional radio station works. By traditional, I mean how stations have worked for many years. That will make it easier to see where automation makes sense.
A typical station is composed of one or more studios and a transmitter facility. A studio is nothing more than a soundproof room with some audio equipment. The transmitter may be in the same building or at a remote location connected by a dedicated wire or radio link. While there is some room for talking about the transmitter link, I want to concentrate on the studio end.
Generally, one studio will be live. That means whatever is happening in that studio will be sent directly to the transmitter. The alternative to a live studio would be the station either re-broadcasting some external feed or something that they have pre-recorded. In any case, whenever the transmitter is on the air, there must be some source of program material. Additional studios are available to build the pre-recorded program material.
Each studio will likely contain one or more live microphones, multiple sources for pre-recorded material (CD players, turntable and tape decks) and something to record a program (tape recorder or mini-disk are the most common). Also included is a audio mixer board and monitor system so multiple sources can be mixed and edited.
Small stations will typically have one studio with a person that queues and starts pre-recorded sources and makes live announcements that can include news and weather. For a typical music station, the majority of this person's time is spent waiting for the current song to end so they can queue the next one possibly inserting some commentary between songs. They may also be logging what they play so the station can pay the necessary royalties.
This is the most obvious piece of the system--replacing the live tedium of queuing CD tracks with an automated system. The most basic step would be to just save all the tracks on a disk in a computer system and allow the person to pre-select what they would like played during a specified time block. This is relatively trivial to do. We can, however, do a lot more than this.
Most stations develop a play list that the live DJs need to follow. This list includes songs that can be played along with guidelines for how often they can be played. Armed with that list, a program could easily make all the necessary decisions to offer what appears to be a random selection of music within the necessary constraints.
Next comes the announcements. They can be divided into:
Automation of commercials is not much different than the music play lists. The primary difference is that there will likely be specific times when a commercial must be broadcast. Nothing magic here--just another type of event to put into a scheduling program.
The live or almost live program material is that which must be put together by a person. For example, a news broadcast. This could either be done live by a person in the studio (or remotely over an Internet connection) or it could be pre-recorded. If the news was pre-recorded as a set of items then later news broadcasts could re-use the appropriate portions of a previous broadcast. In any case, there is still nothing particularly difficult about this--it is just another event to schedule.
I separated out information that could be automated because it is an additional project. That is, it does not have to be part of this original package. Two things come to mind here:
Both of these announcements are really nothing more than building a human voice announcement out of some digital data. Both have been done--it just becomes a matter of integration.
Some stations allow call-in requests. This means a human responds to a request, checks to see if the song is available and hasn't been played more than is considered correct by the play list and then schedules it. This seems like a perfect place to use a web page. Listeners could place the requests and the software would appropriately adjust what was to be played. If the requested material was not available it could advise you of that fact or even order heavily requested material.
While a traditional transmitter is far away from the scope of this project, a transmitter option deserves mention. In my searching for FM broadcast transmitters for a project in Nicaragua I ran across a company that offers an FM broadcast transmitter on a PCI card. They have a new card on the way and I have offered to write the Linux driver for it.
If you saw this project as just fun or something that would work for your college dorm, a card such as this might be just the ticket. You could offer a web interface to select program material and broadcast to nearby FM receivers. Being a radio guy as well as a computer guy, this interests me a lot.
That covers all the pieces from the geek end. But, as I said in the beginning, I want to present a solution rather than a shopping list. That 100mw station in your basement that your family can listen to is not going to be a good commercial customer but tens of thousands of commercial stations certainly could be.
Integrating all the software necessary to offer a solution is the first part. Installation and support comes next. A radio station that has full-time employees running the station and advertisers paying hundreds or thousands of dollars for a commercial will quickly see the benefits of a system such as this. The biggest hurdle will be showing them that the solution will be supported. That is, that their station will not be off the air because they made this choice.
For a small station, this might mean knowing that they could call someone and have them come in and fix a problem. For a larger station it could mean training of on-site personnel. There are other levels of support including spare systems, shared servers and so forth. In other words, an assortment of different markets where the same software is offered but the support potential varies.
That's up to you. I am excited about the project. Unfortunately, I have a "day job" which does not give me the necessary time to put all this together and even if it was together, I don't want to go into the software support business.
My hope is that the right people are out there that want to do the pieces. That is my real reason for writing this article. I am happy to offer input, help set direction, offer a mailing list of discussion forum and even publicize the product. If you are interested in participating, write at phil@ssc.com and let me know your interests. Or go out to the LG Projects Wiki and chime in. Maybe Linux-controlled radio will be here before you know it.
Phil Hughes is the publisher of Linux Journal, and thereby Linux Gazette. He dreams of permanently tele-commuting from his home on the Pacific coast of the Olympic Peninsula. As an employer, he is "Vicious, Evil, Mean, & Nasty, but kind of mellow" as a boss should be.
|
...making Linux just a little more fun! |
By C.E.C. Artime, J.A. Baro |
A traditionally geeky user base has made the free software panorama plenty of scientifical tools. A key feature of scientific work is public defense of reseach methods and results in scientific meetings, and this is usually accomplished by means of oral presentations or posters. Both require the authors to develop some visual support: slide shows for oral presentations, with plenty of tools available (OpenOffice, LATEX,...), and a poster proper for the poster sessions. These take the form of an A0-sized paper sheet, and a visual exposition of the materials involved is crucial.
A general tool for manipulating images, as the GIMP, can be very useful when most of the poster is to be filled with photos and analogic images. Notwithstanding, scientific graphics are best handled with a vectorial graphics tool. This article will present a brief review of tools for incorporating graphics in scientific posters.
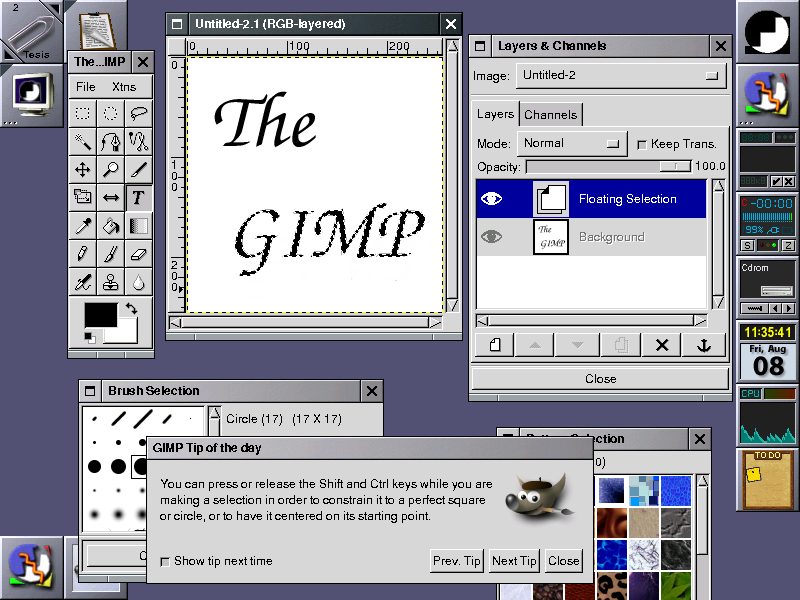
The GIMP is a bitmap- or raster-oriented tool, and as such, aimed at dealing with individual pixels. This approach is suitable for photos and artistic material. Technical drawings take a rather different approach: they are better described by their geometric elements, rather than by their constitutive pixels. This "vectorial" approach has the additional advantage that it produces resolution-independent graphics, thus allowing arbitrary zooming and enlargement.
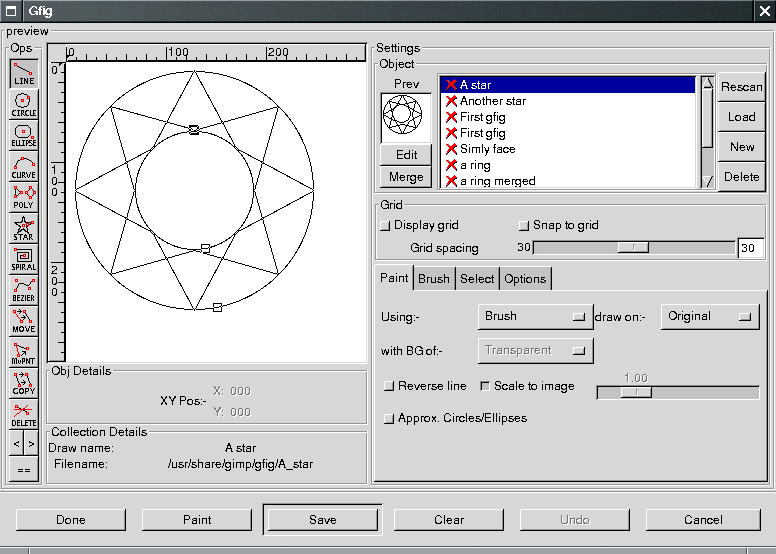
Several free vectorial programs are currently available: Sodipodi, Karbon14, Sketch... Some integrate nicely with the Gnome and KDE desktop environments. Even the GIMP, since version 1.2, includes a plug-in enabling quite elaborate vectorial design, Gfig; it lies under the menu (Filters->Render). However, the classic among X Window applications is Xfig.
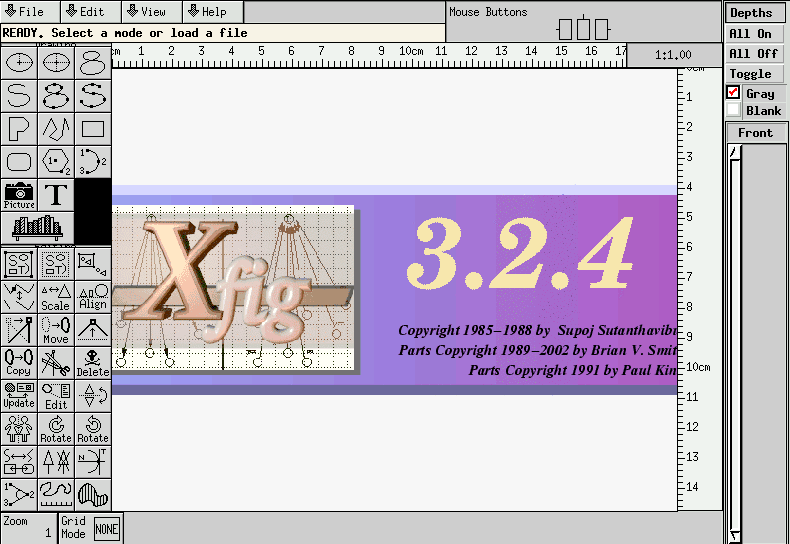
Xfig is a thoroughly proven program that makes use of the X Athena widget toolkit. Thus, it is a very mature product and, consequently, its stability is beyond doubt. This is a highly appreciated feature as work on posters frequently goes on until the very dead line.
A further consequence of being a mature project is that Xfig has been enriched by contributions of a wide community of users. This has produced a comprehensive set of galleries for various fields (electronics, UML, music, maps, etc.).
It is a reliable program as it stores its information in a readily accessible text format, from which information retrieval is quite straightforward. This kind of format does not follow the modern trend, that is, it is not a SGML-based system. Rather, it consists of the minimal amount of information for describing the graphic, stored as ASCII characters. A thorough description is available, e.g., at The FIG file format or, in a Debian system, in the file /usr/share/doc/xfig/FORMAT3.2.gz. Its regularity makes it suitable to be processed with the classical Unix/GNU text filters: sed, awk and such. So chances are that you prefer ASCII to the XML format. On the other hand, important applications as Gnuplot and GNU plotutils can produce FIG files; a comprehensive list is available in the file FIGAPPS, within the Xfig distribution.
Another nice feature of Xfig lies with its ability to export using LATEX friendly formats. This is true for both text and graphics. A “special flag” is assigned to each piece of text, signaling whether it is to be exported 'raw' or 'as TEX'. Graphics are coded according to the LATEX package options chosen by the user. More on this later, so keep reading or look up the LATEX.AND.XFIG and PDFLATEX.AND.XFIG files in the Xfig distribution
In order to be fair, it is time now to expose some not-so-desirable Xfig features. It did not age badly, it is rather that Xfig drags several drawbacks inherited from old techniques.
Users of modern programs will certainly get dissapointed by its single level of undo. So it pays to be a little cautious when designing.
As mentioned above, Xfig makes use of Athena widgets, and suffers from their limilations. For example, it is not easy to handle accented characters in dialog windows (as when using the Edit tool), a very frustrating feature for most European users. Note that it allows the use of the Meta key as a Compose key, thus permitting accented characters when using the Text tool on the canvas.
On the other hand, Xfig handles a lot of export formats. In fact, some of them are especially useful for LATEX users. However, its support for modern graphic formats, like XML-based SGV (Scalable Vector Graphics), is still experimental.
LATEX is a set of macros built on the top of the TEX typesetting system. It is widely used to publish scientific papers, reports and books. Despite many users are unaware, slides are easily composed too. However, designing a full poster with LATEX alone is a daunting task, as many objects must be arranged in a 2D space with possibly complex interconnections among them. So the composition can be visually arranged with Xfig, and lately refined with a TEX editor.
To facilitate the integration of the visual work with the edition of TEX source code, Xfig users are empowered with a broad range of options. First, they have the choice of exporting a file as either a LATEX chunk or as a complete LATEX file. Second, a given graphical element is possibly translated to several TEX expressions, depending of which macros are available or are preferred by the user; this point is discussed in the next paragraph.
The Xfig web site also hosts transfig, which includes a program to export from Fig format to several “devices”, fig2dev. This functionality is available from the GUI as well, under the Export option of the File menu. As we intend to finally automatize the full task as much as possible, emphasis is put on the stand-alone program.
Transformation of Fig documents into TEX elements can be accomplished in several ways. Each way differs in the number of graphical elements it can deal with (for example: rotated text, filled rectangles), at the cost of requiring more sophisticated LATEX packages: epic, eepic, eepicemu, pictex. The best results are obtained with combined PostScript (or PDF) and TeX: this assures that all elements seen in the Xfig screen will be present in the printable output. Two warnings: specially flagged text will be shown as raw TEX in Xfig, but nicely typeset in the final document; and some previewers, as Xdvi (distributed with teTEX), are not able to represent some kinds of elements, as rotated text, so better use dvips and a PostScript viewer.
Processing a TEX file produces by default DVI format files, standing for DeVice Independent. This format is ready to be transformed into the set of displaying instructions. The most widespread format for final documents is PostScript, featuring a complete programming language understood by almost every high-quality printer.
The program dvips converts a DVI file into a PostScript, and is distributed with the main TEX packages, like tetex. It allows several interesting options, giving access to the powerful features of PostScript. One of them is the ability of setting the paper size, be it in a measure unit, as cm, or by a standard name, as A1. This feature is accessed by the -t and -T options.
The output of dvips is fine if one has access to an A0-size capable printer. This is often not the case. An acceptable alternative would be printing 16 A4 pages, or 8 A3 pages. The poster package tiles a one-page PostScript into small pieces, that can be pasted together to form the whole image. Guide lines indicating where to apply the guillotine cutter are printed as well. Poster is available at the KDE web site, and as a Debian package.
Should we give away small copies of our poster, psresize is the tool of choice to build them. It is included in the psutils Debian package.
The entire process must be repeated if any change is made in the Xfig drawing. We suggest that you consider seriously the little extra work of gluing all the steps mentioned through a shell script. Here we present one developed for the most widespread shell, GNU bash. Calling the following script from within the directory containing the Fig file, the whole proccess is performed. Note that it appends a LATEX preamble and postamble, required by several LATEX features used by the author, and several other as required by Xfig exports.
(We just realised the inclusion of a simple script meant to perform the conversion from the Fig format to an EPS, TeXfig2eps, in the Xfig distribution. As our discussion shows, it may not be enough in many cases.)
#!/bin/bash
################################################
# Processes the FIG source file for the poster #
################################################
######################################################
# #
# Usage: #
# 1. Design a poster with Xfig. #
# 2. Save it as a normal FIG file, with #
# the name, e.g., `myfile.fig'. #
# 3. Substitute `BASE=myfile' for the line #
# `BASE=poster' in this script. #
# 4. Run this script within the directory #
# where `myfile.fig' lies. #
# 5. The output files will be: #
# `myfile-a0.ps' - one poster-sized page #
# `myfile-a4-1.ps' - a4-sized mini-poster #
# `myfile-a4-16.ps' - sixteen tile pages #
# #
######################################################
# basename
BASE=poster
# convert the FIG into LaTeX + PostScript
echo '
\documentclass{article}
\usepackage{amsmath} % symbols and equations
\usepackage{amsfonts} % needed for blackboard characters
\usepackage[spanish]{babel} % titles in our language
\usepackage[latin9]{inputenc} % accented characters
\usepackage[a0paper,margin=0cm,nohead,nofoot]{geometry} % margins
\usepackage{graphicx} % including figures
\usepackage{color} % import from Xfig
\usepackage{epic} % complements the following
\usepackage{eepic} % Xfig filling
\usepackage{rotating} % text in figures
\usepackage{type1cm} % arbitrarily sized fonts
\begin{document}
' > $BASE.tex
fig2dev -L pstex $BASE.fig > $BASE.pstex
echo -n '
\begin{picture}(0,0)
\includegraphics{'$BASE'.pstex}
\end{picture}
' >> $BASE.tex
fig2dev -L pstex_t $BASE.fig >> $BASE.tex
echo '\end{document}' >> $BASE.tex
# typeset the source LaTeX
latex $BASE
# transform into a PostScript of size almost DIN A0
dvips -o $BASE-a0.ps -T 84cm,118cm $BASE
# build the small A4 version of the poster
psresize -Pa0 -pa4 $BASE-a0.ps $BASE-a4-1.ps
# build the 16 A4 pages composing the poster
dvips -o $BASE.eps -T 84cm,118cm -E $BASE
poster -mA4 -pA0 $BASE.eps > $BASE-a4-16.ps
Some of the commands used in the script need further explanation.
The following paragraphs try to clarify these issues.
The \usepackage{color} is suggested in /usr/share/doc/xfig/README.Debian in Debian systems. Latest versions of Xfig's pstex use the \RGB command for setting text's color.
Other packages were included as needed, often with a trial and error procedure. The example does not make use of all them, but it can be illustrative as a comprehensive list of packages that we have ever needed for our own posters.
Please note that psresize operates on .ps files, and poster on .eps files. Thus dvips is executed twice, without and with the -E option.
$ xfig -paper a0 -portraitthe canvas adopts the size and orientation of the poster we need. We design a sample poster shown here in a screenshot capture and here in Fig format. We save it with the name poster.fig. The basename poster is assigned to the BASE variable in the first lines of the script. After running the script within the same directory where poster.fig lies, the following output files are of interest:
The standard tetex distribution uses by default bitmapped fonts, which requires discrete magsteps. This leads to warnings like
LaTeX Font Warning: Font shape `OT1/cmr/m/n' in size <30> not available (Font) size <24.88> substituted on input line 5. LaTeX Font Warning: Size substitutions with differences (Font) up to 5.12pt have occurred.As stated in the tetex documentation, \usepackage{type1cm} allows the use of Computer Modern fonts at arbitrary type sizes. It must overwrite font definitions, so it may require to be included after other packages.
Note that transfig uses a fixed set of font sizes, handled through the macro
#define TEXFONTSIZE(S) (texfontsizes[((S) <= MAXFONTSIZE) ? round(S)\
: (MAXFONTSIZE-1))])
that indirectly limits the maximum size of fonts to be of 41
points. For the example being shown, we had to edit
transfig's sources (file texfonts.h) in order to
change that macro to
#define TEXFONTSIZE(S) (S)The Debian way:
$ su Password: # apt-get remove transfig Reading Package Lists... Done Building Dependency Tree... Done The following packages will be REMOVED: transfig 0 packages upgraded, 0 newly installed, 1 to remove and 3 not upgraded. Need to get 0B of archives. After unpacking 799kB will be freed. Do you want to continue? [Y/n] (Reading database ... 67797 files and directories currently installed.) Removing transfig ... # exit $ apt-get source transfig Reading Package Lists... Done Building Dependency Tree... Done Need to get 340kB of source archives. Get:1 ftp://ftp.es.debian.org testing/main transfig 1:3.2.4-rel-4 (dsc) [652B] Get:2 ftp://ftp.es.debian.org testing/main transfig 1:3.2.4-rel-4 (tar) [326kB] Get:3 ftp://ftp.es.debian.org testing/main transfig 1:3.2.4-rel-4 (diff) [13.0kB] Fetched 340kB in 1m51s (3062B/s) dpkg-source: extracting transfig in transfig-3.2.4-rel $ vi transfig-3.2.4-rel/fig2dev/dev/texfonts.h $ cd transfig-3.2.4-rel/ $ dpkg-buildpackage -rfakeroot -uc -us ... [lots of output] ... $ cd .. $ su Password: # dpkg -i transfig_3.2.4-rel-4_i386.deb Selecting previously deselected package transfig. (Reading database ... 67734 files and directories currently installed.) Unpacking transfig (from transfig_3.2.4-rel-4_i386.deb) ... Setting up transfig (3.2.4-rel-4) ... # exit
If you find this method cumbersome, you can have a look at this directory where a style file meant to produce big fonts for big pages (posters) can be found.
![[BIO]](../gx/2002/note.png) C.E.C. Artime is a GNU fan and a free software advocator since 2000.
C.E.C. Artime is a GNU fan and a free software advocator since 2000.
J.A. Baro is a Linux user and a Perl hacker since 1996.
|
...making Linux just a little more fun! |
By Pramode C.E |
In last month's article, I had explored the problems associated with writing timing sensitive code under Linux and looked at how RTAI solves them in an elegant manner. In this issue, I present an interesting application developed by a few of my students as part of a Computer Vision project. I would also like to share with you a few programs which I wrote in my effort to understand RTAI better:
In his article Creating a web page controlled 2-axis movable camera with RTLlinux/Pro, Cort Dougan presents the software and hardware involved in the construction of an interesting device which allows him to always keep an eye on his pet cat, Kepler. An ordinary web cam is controlled by two servo motors - one makes the cam move up and down and the other makes it sweep 180 degrees. The movement of both the servos is controlled by real time tasks.
Motivated by the article, a few of my students tried their hand at designing such a system. Here is what they came up with:

The top and bottom servo's should be clearly visible - the one at the bottom serves to rotate the platform resting on its axis (the platform on which the webcam is mounted). The whole thing is made out of transparent plastic. Here is a closer view of the bottom part:

A hobby servo motor(like the Futaba S2003 used in this project) runs off 5V DC, has high torque for its size and can be positioned at points along a 180 degree arc (or a little bit more - the servo doesn't rotate the full 360 degrees, there is some kind of mechanical `stop' built into it - which can of course be removed if you are seriously into servo hacking). The control wire (normally white colour) of the servo should be continuously fed with a digital signal whose period is about 20ms - the period need not be very accurate, and can be lesser than 20ms, but the on time should be precisely controlled, it is what decides where the servo will move to - in this case, it was seen that the servo moves for about 170 degrees for an on time from 2.2ms down to 0.5ms. Here is a picture of the control pulse:
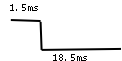
Generating this control pulse with `normal' Linux is a difficult issue - other activities going on in the system can seriously disturb the waveform - with the result that the servo will start reacting violently. So, hard real time RTAI tasks are used.
Two real time tasks are used to control the servos - one controlling the top servo and the other one, the bottom servo. The servo position is communicated to the real time tasks from user space with the help of two real time fifos. Let's first look at some macro/variable definitions (the actual rotation angles have not been accurately measured - so users of the Futaba S2003 need not be worried about any numerical discrepancy):
#define BOTTOM_SERVO_FIFO 0 #define TOP_SERVO_FIFO 1 #define FIFO_SIZE 1024 #define BOTTOM_SERVO 0 #define TOP_SERVO 1 #define BOTTOM_SERVO_PIN 2 /* Bit D1 of parport o/p register */ #define TOP_SERVO_PIN 4 /* Bit D2 of parport o/p register */ #define TICK_PERIOD 1000000 /* 1 ms */ #define STACK_SIZE 4096 #define MIN_ON_PERIOD 500000 /* .5 ms */ #define NSTEPS 35 #define STEP_PERIOD 50000 /* 50 micro seconds */ #define TOTAL_PERIOD 20000000 /* 20ms */ #define ONE_SHOT RTIME on_time[2], off_time[2]; RT_TASK my_task1, my_task2;The bottom servo is connected to pin 3 of the parallel port and the other one, to pin 4 - the macro's BOTTOM_SERVO_PIN and TOP_SERVO_PIN define the values to be written to the parallel port data register to set these pins (bit D0 of parallel port data register controls pin number 2, bit D1 pin number 3 and so on - the macro's are definitely poorly named and meant to confuse readers). The minimum on period of the control pulse is defined to be 500000 nano seconds (.5 ms). Because we get a servo rotation of 170 degree for pulse widths from 0.5ms to 2.2ms, a 50 micro second change in pulse width gives us 5 degree of rotation. We define the `zeroth step' of the servo as the position to which it moves when it sees a pulse of 0.5ms duration and the `thirty-fourth step' as the position it moves to when it sees a pulse whose on time is 0.5ms + (50 micro second * 34), ie, 2.2ms. So, in a total of 35 steps, each step about 5 degree, we get full 170 degree rotation. What the user program communicates with the real time tasks through the fifos is this step number.
The total period is defined to be 20ms. The zeroth element of the on_time array stores the current on time of the pulse which controls the bottom servo and the first element, that of the top servo. Similar is the case with the off_time array.
Let's now look at the code for the tasks which control the servo's:
static void servo_task(int pin)
{
while(1) {
outb(inb(0x378) | pin, 0x378);
rt_sleep(on_time[(pin >> 1) - 1]);
outb(inb(0x378) & ~pin, 0x378);
rt_sleep(off_time[(pin >> 1) - 1]);
}
}
The argument to the task is BOTTOM_SERVO_PIN or TOP_SERVO_PIN,
depending on which servo it controls. The servo number can be
obtained from these values by shifting them right once and subtracting
one. First, the corresponding parallel port pin is made high and
a sleep is executed - then, the pin is made low and the task goes
to sleep once again.
Let's now look at the fifo handler code - user programs communicate with the real time tasks through two fifo's - one for each servo. The fifo handler code, which gets executed when either of them is written to from a user space program, is the same. User programs communicate a `step number', ie, an integer in the range 0 to 34.
int fifo_handler(unsigned int fifo)
{
int n, r;
unsigned int on;
r = rtf_get(fifo, &n, sizeof(n));
rt_printk("fifo = %d, r = %u, n = %u\n", fifo, r, n);
if((n < 0) && (n > 34)) return -1;
on = MIN_ON_PERIOD + n*STEP_PERIOD;
on_time[fifo] = nano2count(on);
off_time[fifo] = nano2count(TOTAL_PERIOD - on);
return 0;
}
The code should be easy to understand, it simply reads a step number,
converts it into a corresponding `on time' and stores it into the proper
slot in the on_time array. The argument to the handler is the number
of the fifo to which data was written to from the user space program.
We now come to the module initialization part, the code should be easy to understand.
int init_module(void)
{
RTIME tick_period;
RTIME now;
rtf_create(BOTTOM_SERVO_FIFO, FIFO_SIZE);
rtf_create_handler(BOTTOM_SERVO_FIFO, fifo_handler);
rtf_create(TOP_SERVO_FIFO, FIFO_SIZE);
rtf_create_handler(TOP_SERVO_FIFO, fifo_handler);
#ifdef ONE_SHOT
rt_set_oneshot_mode();
#endif
rt_task_init(&my_task1, servo_task, BOTTOM_SERVO_PIN, STACK_SIZE, 0, 0, 0);
rt_task_init(&my_task2, servo_task, TOP_SERVO_PIN, STACK_SIZE, 0, 0, 0);
tick_period = start_rt_timer(nano2count(TICK_PERIOD));
on_time[BOTTOM_SERVO] = nano2count(MIN_ON_PERIOD);
on_time[TOP_SERVO] = on_time[BOTTOM_SERVO];
off_time[BOTTOM_SERVO] = nano2count(TOTAL_PERIOD - MIN_ON_PERIOD);
off_time[TOP_SERVO] = off_time[BOTTOM_SERVO];
now = rt_get_time() + tick_period;
rt_task_make_periodic(&my_task1, now, tick_period);
rt_task_make_periodic(&my_task2, now, tick_period);
return 0;
}
And here comes the module cleanup:
void cleanup_module(void)
{
stop_rt_timer();
rt_busy_sleep(10000000);
rtf_destroy(BOTTOM_SERVO_FIFO);
rtf_destroy(TOP_SERVO_FIFO);
rt_task_delete(&my_task1);
rt_task_delete(&my_task2);
}
The real time tasks were found to control the servo's perfectly. The system was heavily loaded by running multiple kernel compiles, copying and untarring large files and several other tricks - but the real time tasks were found to perform satisfactorily.
It is easy to measure the frequency of a low-frequency square wave. Simply apply it to the parallel port interrupt pin, write an interrupt service routine and increment a count within the routine. This count may be transferred to a user space program through a real time fifo.
A real time application may not tolerate interrupts getting missed or the interrupt handling code getting executed a long time after the interrupt is asserted. With a `normal' Linux kernel, this is a real problem. The Linux kernel may disable interrupts when it executes critical sections of code - during this time, the system remains unresponsive to external events. In an RTAI patched kernel, even if Linux asks for interrupts to be disabled, interrupts don't really get disabled; only thing is RTAI does not let the Linux kernel see the interrupt. A real time task will still be able to handle interrupts undisturbed.
Here is a small program which counts the number of interrupts coming on the parallel port interrupt input pin. I tested it out by using a function generator to generate a square wave at various low frequencies. A simple 555 timer based circuit should also do the job.
#include <linux/module.h>
#include <rtai.h>
#include <rtai_sched.h>
#include <rtai_fifos.h>
#include <asm/io.h>
#define FIFO_R 0
#define FIFO_W 1
#define TIMERTICKS 1000000000 /* 1 second */
#define STACK_SIZE 4096
#define FIFO_SIZE 1024
static int prev_total_count = 0;
static int new_total_count = 0;
static RT_TASK my_task;
static void fun(int t)
{
while(1) {
prev_total_count = new_total_count;
new_total_count = 0;
rt_task_wait_period();
}
}
int fifo_handler(unsigned int fifo)
{
char c;
rtf_get(FIFO_R, &c, sizeof(c));
rtf_put(FIFO_W, &prev_total_count, sizeof(prev_total_count));
return 0;
}
static void handler(void)
{
new_total_count++;
}
int init_module(void)
{
RTIME tick_period, now;
rt_set_periodic_mode();
rt_task_init(&my_task, fun, 0, STACK_SIZE, 0, 0, 0);
tick_period = start_rt_timer(nano2count(TIMERTICKS));
now = rt_get_time();
rt_task_make_periodic(&my_task, now + tick_period, tick_period);
rtf_create(FIFO_R, FIFO_SIZE);
rtf_create(FIFO_W, FIFO_SIZE);
rtf_create_handler(FIFO_R, fifo_handler);
rt_request_global_irq(7, handler);
rt_enable_irq(7);
outb(0x10, 0x37a);
return 0;
}
void cleanup_module(void)
{
stop_rt_timer();
rt_busy_sleep(10000000);
rt_task_delete(&my_task);
rt_disable_irq(7);
rt_free_global_irq(7);
rtf_destroy(FIFO_R);
rtf_destroy(FIFO_W);
}
The rt_request_global_irq and rt_enable_irq functions together instruct the RTAI kernel to service IRQ 7 (which is the parallel port interrupt). The interrupt handler simply increments a count. Every 1 second (the frequency of our input doesn't change fast, and we are only interested in observing a long cumulative count) a real time task wakes up and stores this count value to another variable (called prev_total_count) and also clears the counter. User programs can access prev_total_count through a FIFO.
A user program reads the count by writing a dummy value to FIFO_R and reading from FIFO_W. Writing to FIFO_R will result in fifo_handler getting executed, which will place the count onto FIFO_W; it can then be read by the user program. There should surely be a better way to do this - only trouble is, I don't know how. Here is the user program:
/* User space test program */
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#define FIFO_W "/dev/rtf0"
#define FIFO_R "/dev/rtf1"
main()
{
int fd1, fd2, dat,r;
fd1 = open(FIFO_W, O_WRONLY);
fd2 = open(FIFO_R, O_RDONLY);
assert(fd1 > 2);
assert(fd2 > 2);
write(fd1, "a", 1);
r = read(fd2, &dat, sizeof(dat));
assert(r == 4);
printf("interrupt count = %d\n", dat);
}
Let's say we wish to measure the off-time of a pulse of total width 3ms with an accuracy of not more than 0.1ms. We start a periodic task with period 0.1 ms. At each `awakening' of this periodic task, it checks whether the signal is low or high. The number of times the signal is low, out of a total of 30 samples, is recorded. Here is the code which implements this procedure:
#include <linux/module.h>
#include <rtai.h>
#include <rtai_sched.h>
#define LPT1_BASE 0x378
#define LPT1_STATUS 0x379
#define ACK 6
#define STACK_SIZE 4096
#define TIMERTICKS 100000 /* 0.1 milli second */
#define TOTAL_SAMPLES 30 /* Take 30 samples at 0.1 ms each */
static RT_TASK my_task;
static int old_off_samples, new_off_samples;
static void fun(int t)
{
static int count = 0;
while(1) {
new_off_samples = new_off_samples + ((inb(LPT1_STATUS) >> ACK) & 0x1);
if(++count == TOTAL_SAMPLES) {
count = 0;
old_off_samples = new_off_samples;
new_off_samples = 0;
}
rt_task_wait_period();
}
}
int init_module(void)
{
RTIME tick_period, now;
rt_set_periodic_mode();
rt_task_init(&my_task, fun, 0, STACK_SIZE, 0, 0, 0);
tick_period = start_rt_timer(nano2count(TIMERTICKS));
now = rt_get_time();
rt_task_make_periodic(&my_task, now + tick_period, tick_period);
return 0;
}
void cleanup_module(void)
{
stop_rt_timer();
rt_printk("old = %u, new = %u\n", old_off_samples, new_off_samples);
rt_busy_sleep(10000000);
rt_task_delete(&my_task);
}
The periodic task checks the D6th bit of the parallel port status register. It is 1 if the input signal on the 10th pin is low. The count could be, as usual, transferred to a user space program through a fifo.
Programmer's use semaphore's to synchronize the activity of multiple threads. RTAI has a function:
void rt_sem_init(SEM *sem, int value);Which can be used to create and initialize semaphore objects. There is an interesting problem called `priority inversion' associated with the use of locking mechanisms in an an environment which allows preemptive execution of tasks with varying priorities. It seems that the problem was brought to the attention of the real time design community by certain glitches encountered during the Mars Pathfinder Mission (a Google search would yield more information). I shall try to describe the problem first (the description is based on information obtained from the Net on the Pathfinder mission failure).
Suppose we have a very high priority task, Task-H which periodically accesses a buffer to write data to it (or read data from it). Another task, a very low priority and very infrequently running task, which always runs only for a short amount of time (let's call it Task-L), also might need to access the buffer to write to or read from it. Both these tasks would have to successfully grab a lock before one of them is able to access the buffer; the lock can be acquired by only one task at a time. Let's say Task-L grabs the lock and starts accessing the buffer. In between, suppose an interrupt causes the scheduling of the very high priority task, Task-H. Now, Task-H also would try to grab the lock, but blocks because it is currently held by Task-L. In the normal case, Task-L would finish very soon and release the lock, allowing Task-H to continue. But suppose a medium priority task, Task-M gets scheduled. Now, as long as Task-M does not finish, the OS will not allow Task-L to continue. Only if Task-L finishes doing whatever it has to do and releases the lock will Task-H be able to continue - the result is Task-H gets delayed by the time Task-M would take to complete. Suppose the system designer overlooks this and builds a watchdog timer which would time out and reboot the system if Task-H does not run for a short amount of time - the result would be system reboots whenever Task-M comes in between Task-H and Task-L.
Here is a small program which tries to demonstrate this problem.
#include <linux/module.h>
#include <rtai.h>
#include <rtai_sched.h>
#define LPT1_BASE 0x378
#define STACK_SIZE 4096
#define TIMERTICKS 100000000 /* .1 second */
#define HIGH_PRIO 0
#define MEDIUM_PRIO 1
#define LOW_PRIO 2
#define PORTB 0x61
#define PIT_CTRL 0x43
#define PIT_DATA 0x42
static RT_TASK my_task1, my_task2, my_task3;
SEM flag;
RTIME tick_period;
unsigned char c = 0;
void speaker_on(void)
{
unsigned char c;
c = inb(PORTB)|0x3;
outb(c, PORTB);
}
void speaker_off(void)
{
unsigned char c;
c = inb(PORTB)&~0x3;
outb(c, PORTB);
}
void generate_tone(void)
{
/* Counter 2, low and high, mode 3, binary */
outb(0xb6, PIT_CTRL);
outb(152, PIT_DATA);
outb(10, PIT_DATA);
}
static void my_delay(unsigned int i)
{
while(i--);
}
/* Highest priority */
static void info_bus_task(int t)
{
speaker_on();
rt_sem_wait(&flag);
rt_printk("info bus task got mutex...\n");
rt_sem_signal(&flag);
speaker_off();
}
/* Medium Priority */
static void comm_task(int t)
{
my_delay(0xffffffff);
my_delay(0xffffffff);
my_delay(0xffffffff);
}
/* Low priority */
static void weather_task(int t)
{
rt_sem_wait(&flag);
rt_sleep(30*tick_period);
rt_sem_signal(&flag);
}
int init_module(void)
{
RTIME now;
//rt_typed_sem_init(&flag, 1, RES_SEM);
rt_sem_init(&flag, 1);
rt_set_periodic_mode();
generate_tone();
rt_task_init(&my_task1, info_bus_task, 0, STACK_SIZE, HIGH_PRIO, 0, 0);
rt_task_init(&my_task2, comm_task, 0, STACK_SIZE, MEDIUM_PRIO, 0, 0);
rt_task_init(&my_task3, weather_task, 0, STACK_SIZE, LOW_PRIO, 0, 0);
tick_period = start_rt_timer(nano2count(TIMERTICKS));
now = rt_get_time();
rt_task_make_periodic(&my_task1, now + 2*tick_period, tick_period);
rt_task_make_periodic(&my_task2, now + 3*tick_period, tick_period);
rt_task_make_periodic(&my_task3, now + tick_period, tick_period);
return 0;
}
void cleanup_module(void)
{
stop_rt_timer();
rt_busy_sleep(10000000);
rt_sem_delete(&flag);
rt_task_delete(&my_task1);
rt_task_delete(&my_task2);
rt_task_delete(&my_task3);
}
The information bus, communication and weather tasks are respectively
the high, medium and low priority tasks. RTAI lets us set priorities
to tasks during rt_task_init. The weather task starts first. It grabs
a semaphore (the semaphore is initialized to 1 in rt_sem_init) and
then goes to sleep for 30 ticks (3 seconds, as each tick is 0.1 second).
The information bus task runs at the next timer tick (the second argument
to rt_task_make_periodic is the point of time at which the task is to be
started); it turns on the PC speaker and then attempts to do a `down'
operation on the semaphore and in the process, gets blocked. We expect the
weather task to complete its sleep, release the semaphore and let the
information bus task run to completion, thereby stopping the noise coming
out of the speaker. But the trouble is that before the weather task comes
out of its sleep, a medium priority `communication' task gets scheduled and
starts executing a series of busy loops (which on my Athlon XP system generates a
combined delay of about 17 seconds when compiled with -O2 - it would be better if you time the delay
loop in a userland program before you plug it into the kernel - remember, as
long as that delay loop is running, your machine will be in an unusable state -
so be careful with what you do). The operating system can't bring the weather
taks out of its sleep even after 3 seconds is over because the medium priority
task is busy executing a loop - after about 17 seconds, the communication task
would end, thereby letting the weather task continue with its execution. The
weather task perform an `up' operation on the semaphore bringing the information
bus task out of the block and letting it stop the speaker. We note that the
high priority information bus task is getting delayed by the communication task.
RTAI supports `resource semaphores' - they can be used to solve the above problem. Had we initialized our semaphore like this:
rt_typed_sem_init(&flag, 1, RES_SEM);the task which originally `acquired' the semaphore (the weather task) would have `inherited' the priority of the high priority information bus task blocked on it. This would have resulted in the RTAI scheduler preempting the communication task and giving control back to the weather task exactly after 3 seconds of sleep.
The webcam-servo motor setup was implemented by Krishna Prasad, Mahesh and friends as part of a Computer Vision project; they wish to acknowledge the influence of Cort Dougan's implementation of the idea on RTLinux. RTAI comes with good documentation, and lots of example code. I would like to thank all those people who took the pains not only to build a great system, but also document it well.
I have been teaching GNU/Linux and elementary Computer Science since 1997. If you are sure that you really wish to waste your time, you might drop in on my home page pramode2.tripod.com
I am an instructor working for IC Software in Kerala, India. I would have loved
becoming an organic chemist, but I do the second best thing possible, which is
play with Linux and teach programming!
|
...making Linux just a little more fun! |
By David Dorgan |
A quick and dirty guide to debugging tcp/ip
This is a small guide I wrote into debugging TCP/IP networks. It assumes you are using linux, or other unix like o/s.
So it's 5pm on a Friday, a user says he/she cannot connect to $some-web-site, What do you do? There are a few paths, often internal and external sites will require a different approach.
Some things won't change, think if it this way, if layer 1 (physical) isn't working, everything on top of that isn't going to work, it's a good idea to use a number of tools, like telnet, ping, traceroute, tracepath etc... to see where the problem is, and if you can, what layer it's ok. Say if you can ping and traceroute fine to a host, you can get to port 25, but not port 80, then the chances are it's just their webserver dying. Say you can't get past your local gateway, but you can ping you local gateway, it could be the case that it's not forwarding, it's a firewall configuration issue etc...
Try and telnet to thesite.com on port 80, to see if you can connect, if you get connection refused and you don't have any firewalls or proxys blocking outbound communication, the chances are they are having some sort of service outage. If it just stays there for a while and then says 'cannot connect' then continue.
Try and ping the remote side, although this is very useful, some places do block ICMP (they must be under the impression that while creating tcp/ip, for the first six days most of the work was done, and they had nothing to do on Sunday, so they invented ICMP as a joke), so you could try a traceroute, once again this could be blocked, but it'll generally give you a picture of where the problem is. At this point, look at see where it stops, you should see your local gateway and maybe some internal routers of gateway devices, after this you should see it going through ISP networks, if you don't see your ISP anywhere and it stops on the first few hops, it could be a problem with the link to your ISP, if it shows your ISP and then shows an outage just after your ISP's name, maybe the ISP has lost the link to one of their upstreams and the old paths are still valid so packets are being stopped there. Finally you may see it go all the way to the other side, and finish totally, or stop on somecompany-gw.customer.isp.net, in which case the other side may be blocking inbound ICMP.
If they can't seem to connect to anything, ask them to try with an IP, if this works, get them to check their DNS settings.
Some common traits of certain events.
A service dying but the network being fine: If you can ping and traceroute fine, and you can connect to other open ports, say the machine does mail and remote access, if you can get to port 22 (ssh) fine but not port 25 (smtp) there could be a problem with the MTA only.
A firewall blocking a port: This doesn't work so well when routers or firewalls have a 'deny all' by default, but most people don't do that. Let's say you can't get to port 25 on this machine, when you telnet, it just times out, but you know it's a mailserver, try to telnet to a few ports, just random high number ports, like 8274 or 9274 and see if you get connection refused. If you get connection refused, the chances are the firewall is just blocking port 25 due to your IP, because the machine responded that you couldn't get on those ports.
The link to your ISP is dead: Try and traceroute to anywhere, and you will see that the last hop that doesn't time out is an internal one from your company, and that you never see anything with link-whatever.isp.net.
The link is gone on the other side: In this case, maybe you know they don't block traceroute packets, so when you do traceroute, it goes through your isp, to a carrier, to their isp and then stops on what is normally their ISP's link.
Your ISP is having a routing issue: This often happens with some providers *ahem*, I have accounts on a few machines, based in physically different locations and using different providers, so if I can't get to a resource I want, ill try and traceroute it from a machine hanging straight off LINX and a few just off some US ISP's, if they all seem to work from there, and a traceroute from you shows timeouts or unusually high latency in say london.isp.net, then their links to london maybe overused or having issues.
It's taking about two minutes to login to a machine: When you do login, type w or who, and check to see if it says you are coming from an IP or hostname? It shouldn't say hostname, basically it's waiting that long on DNS, it should use an internal DNS server that will reply quickly, or else you should use reverse lookups for IP addresses.
Somebody is complaining they can't connect to a service, you try a manual connection from an outside host and it doesn't work. Then go onto the machine and try and telnet to the port or do an netstat -an | grep LISTEN and look for the port number it should be listening on. If it is there, it could be filtered somewhere along the path, or even at the local host. If it isn't listen, then doing an fstat or lsof and and grepping for the process name may show IPv4 or internet entry, showing the ip address and host it's listening on.
$Id: debugging-tcpip.html,v 1.5 2003/09/18 18:33:47 davidd Exp $
David has been a very productive writer and plans to contribute more of his
work in the future.
|
...making Linux just a little more fun! |
By David Dorgan |
Monitoring and Graphing Applications with SNMP and MRTG. |
$Id: dirty-snmp.html,v 1.4 2003/08/30 15:00:35 davidd Exp $
David has been a very productive writer and plans to contribute more of his
work in the future.
|
...making Linux just a little more fun! |
By David Dorgan |
The state of software security.
Note, this is just a alpha document , I am going to work more on this.
Computer security today is appalling. It is awful, there are worms all the time, there are ones to attack your email, maybe it's an irc network, maybe it's just a flood of traffic, the situation is getting out of control, and I've not seen any 'security' company help, in fact, they are making things worse, 'how much worse?' allot worse, there are lots of hosts infected right now, and when an owner gets pissed, he hits you. The openssh bug recently was first presented at defcon of this year, and was supposed to be known within ’some circles’ for over a year. I wonder how many of those exist right now?.
I am fast becoming disillusioned with software security. It seems like an uphill battle which just isn't being won. Every company offers the silver bullet, and most users accept that. I'll take an example, recently there have been some virus outbreaks, now allot of machines got infected, and the worm pinged allot of hosts before it infected, in fact it would only try and infect those who replied. This caused a DoS attack on the clients site very often, it seems to have started on the subnet you are on, some if some guy had a laptop and popped behind a 192.168.x.x network, it would try and infect the whole network. The patch site that MS run was very slow due to the demand, 'but what about anti virus software?' Personally I think if the ISP detected this worm on a customers network it should have disconnected their network and then fined the user for wasting their time.
There are some problems with antivirus software,
Now after that recent scare, some 'internet patch' crap did the rounds, and some IDIOTS actually clicked on the .exe file, of course they can plead ignorance. But if I get a car and smash it into somebody, I can't plead ignorance, there is NO liability put on the end user in computing, there is NO liability on software quality put on the vendor. In fact, if you want to think about how careless vendors are, visit this page on Unpatched IE security holes.
Allot of this could be stopped by a tiny amount of clue, in programming, WHY USE STRCPY if you are using C, if you are teaching C in college, DON'T LET ANYBODY USE THEM! Fail anybody who does use them. In the testing phase of code, fail anybody for using these, if they are silly enough to use strcpy for input from a user for example, imagine the possible amount of race conditions, format string overflows etc...
For the end user, do not click on executable files, just don't, don't ask why, who cares who it's seemed to have been sent from, don't execute it, or pif files, or bat files, or scr files etc. Why use word documents? HTML is cross platform, looks great etc...
It's going to get allot worse before it gets better, imagine 1000 of those sobig worms around, not just one. Imagine lots of more infected flying around and stupid software replying to each one, to mailing lists with 100,000 people on them. The future of secure computing isn't coming from vendors such as symantec, that's one thing I do know, and I really believe this after some really stupid statements that some of their 'leaders' have come out with.
$Id: security.html,v 1.7 2003/10/03 17:34:27 davidd Exp $
David has been a very productive writer and plans to contribute more of his
work in the future.
|
...making Linux just a little more fun! |
By David Dorgan |
It has come to my attention that a lot of people like using ssh,
most do not use keys, some do. What struck me is that most of the
people who do use keys don't use passphrases with them, when I
asked some people why not, they said they didn't like typing their
password each time, this isn't the case. |
$Id: ssh-with-keys.html,v 1.4 2003/08/30 15:00:35 davidd Exp $
David has been a very productive writer and plans to contribute more of his
work in the future.
|
...making Linux just a little more fun! |
By David Dorgan |
Useful features of screen
This is a very basic introduction to some of useful features of screen.
I learned to use screen after I saw what it could do, it has some very good uses, basically screen is a screen manager with terminal emulation. The best way to see how it works and how it could be useful for you, is to use it. I'll give you one reason why I use it, I use irc allot, I don't mind idling and letting my client stay on, or sometimes I used to leave it on and then have to kill the connection if nickserv was available on that server, but with screen I login from a server I use, I just login and 'attach' the session, and I can detach it and reattach from any machine I like, because the virtual screen is always there.
For a really basic example, install screen, then run screen
by typing screen,once inside this type vim myfile.c,now
type Ctrl A, and then hit the dkey. Now you should
be back at your normal shell, now type screen -list , and you will see there
is one screen session belong to you, now type screen -xto reattach
this session. Now you will see the same session, now if you have an account
on a remote host, maybe login and do the same with IRC, then detach and
reattach, and you will see all the new messages too, and you can do this with
any terminate application from anywhere, useful isn't it?
Now just so that you know, you can have a few sessions running and one easy way of re-attaching would be do to a screen -list and then screen -R $screen_number .There are betters ways to handle this, but for more information on that in the screen man page.
Now say you want more than one shell per screen session,
start screen, then type echo 'this is number one' ,then type
Ctrl-Aand n, now you should see another new window,
now hit ctrl-a and0,you should now be back to your
first terminal, you can create a number of these, to destroy one just type
ctrl-a and k, ctrl-a and p will bring you to the pervious
window and ctrl-a n will bring you to the next. For help type ctrl-a ?
.
There are many other things you can do, just read the man page.
$Id: using-screen.html,v 1.3 2003/08/30 15:00:35 davidd Exp $
David has been a very productive writer and plans to contribute more of his
work in the future.
|
...making Linux just a little more fun! |
By Nikhil Bhargava |
I am Nikhil Bhargava from Delhi, India. I am a computer engineer and curently working in CDOT, India for past one year.
|
...making Linux just a little more fun! |
By Michael Baxter |
Dr. Boulanger has been associated with Csound for a long time, and is the editor of The Csound Book (see resources), an excellent resource consisting of multiple contributions from the Csound community for learning and using Csound. In a chat with Dr. Boulanger, we provide perspective on one of the oldest C-based software sound synthesis environments. This in-depth interview complements Dave Phillips' recent article (see May 2003 LJ, page 80) about the newest Linux softsynth environments.
Q: Dr. Boulanger, thank-you for your time. Four years ago _Linux Journal_ ran an article by David Phillips on Csound on Linux. Could you describe some of the advances to Csound since that time?
A: As you know, Michael, Csound is arguably the most powerful cross-platform software synthesis and signal processing system available today. It's incredible, it continues to grow and improve, and most importantly, it's free! Although many commercial applications such as Max/MSP, PD, SuperCollider, Tassman, and Reaktor are getting closer and closer to Csound's programability, power and functionality, nothing comes close - especially given all the platforms and operating systems upon which one can run the very same Csound orchestras, scores, and instruments.
And you are right, I have been composing with, teaching with, and writing about this incredibly powerful and versitile program for over 25 years now. I started studying at the MIT Experimental Music Studion in 1979 with Barry Vercoe. There I was doing sound design and composition using Barry's music11 program - essentially Csound for the PDP11 minicomputer. That very first music11 composition of mine - "Trapped in Convert" has been presented in concerts all over the world - including Alice Tully Hall in New York - quite a big deal for a then budding young composer! When I returned to the MIT Media Lab in 1986 with my Computer Music Ph.D. in hand, I worked with Barry betatesting his new language - Csound. We would use "Trapped" to make sure that all the opcodes were working correctly.
In fact, the version of "Trapped in Convert" that people render and tweek today was the very first Csound piece. And what is so important to me is that this very same piece (http://csounds.com/compositions/colleaguezip/Trapped.zip) can be rendered and studied today using a version of Csound that runs on virtually any computer. Back in 1979, it took hours to render each sound and gesture, days to render each phrase and section, and weeks to render the entire four and a half minute piece - at 24K! Today, at 44.1K, "Trapped in Convert" renders in realtime on virtually any PC.
For me, the ability to preserve the history of computer music composition and sound design is extremely important. Much of the music I composed using sequencers, synthesizers and MIDI equipment during the 80's and 90's has been retired and lost when the gear was sold, broke-down, or the computers running early sequencers and sound editers were retired to the basement. Getting rid of an old computer usually meant tossing out your music too. Yet, the very fact that I can still render, "tweek," and teach with my old Csound pieces is a testament to Csound's greatness. For me at least, Csound has proven to be future-proof. In fact, since Csound is a direct decendent of the MusicN languages developed by Max Mathews at Bell Labs in the late 50's, the entire history of computer music research is preserved in this program. Many of the classic pieces and classic instrument design catalogs, by Risset for instance, have been totally reconstructed in Csound and can be rendered, studied, and modified to this day.
Since Dave Phillips' wonderful Linux Journal article on Csound, there have been a number of important milestones. Several Csound Books have been published - The Csound Book (MIT Press), Virtual Sound (ConTempo), and Cooking with Csound (AR Editions). The Csound Instrument Catalog has been released with thousands of models to study and modify. The quarterly Csound Ezine has been a regular source of inspiration and undertanding. Extensive Csound tutorials have been featured in Keyboard and Electronic Musician Magazines. In addition to The Csound mailing list, two new Csound mailing lists have been started - the csoundTekno list, and the csoundDeveloper's list. The international Csound community of Csound teachers, users, and developers has really grown and their cSounds have gone mainstream - featured in major Hollywood films (Traffic, Black Hawk Down, Narc), and an number of Computer Games. Dave Phillips himself has finished a wonderful book, "The Book of Linux Music and Sound" that features some wonderful stuff on Csound and related applications and utilities that is a real help for newcomers to the Linux audio world.
In the last four years, there have been some incredibly developments to Csound by the key platform developers and maintainers. Barry Vercoe continues to develop proprietary versions of Extended Csound for embebed systems and Analog Devices DSP chips. Matt Ingalls continues to push the Macintosh versions of Csound in wonderful ways. His MacCsound has user defined GUI Widgets built into the launcher, support for instruments as plugins, and super clean MIDI (at last!). Even cooler, his csound~ external for Max/MSP and PD essentially embed the entire Csound language into the Max/MSP/Jitter and PD/GEM graphical programming environments and thus add incredibly interactivity, estensive algorithmic capabilities, super MIDI, and multichannel/low-latency ASIO support to Csound on the Mac. Sound Designers and Composers such as Joo Won Park, Sean Meagher, and Takeyoshi Mori have developed wonderful real-time GUI-based applications such as CsoundMax, CsoundFX, and CsoundMixer.
Michael Gogins has been busy with CsoundVST, a version of Csound that runs as a VST plugin in Cubase and Nuendo for the PC. Most recently he completely embedded Csound into his algorithmic composition language SilenceVST that can run stand-alone or be hosted by the PC versions of Cubase or Nuendo. He has also done some extensive collaboration with Matt Ingalls to define a preliminary Csound API.
Gabriel Maldonado's CsoundAV for Windows has ASIO support and adds hundreds of openGL and GUI opcodes to the language. It is incredible to make audio instruments that communicate with GUI instruments all from the same Csound orchestra and all with the same exact syntax! A number of Csound's top sound designers such as Luca Pavan, Josep Comajuncosas, Oeyvind Brandtsegg, and Alessandro Petrolati have developed an arsenal of incredible GUI-based real-time applications, instrument, and effect collections.
Somewhat controversial and radically new and expanded Linux versions of Csound were developed by Maurizio Umberto Puxeddu (iCsound), and are currently under extensive development by Istvan Varga.
And behind the scenes, John ffitch, with some help and support of Richard Dobson, has been maintaining, improving, and extending Canonical Csound FOR ALL PLATFORMS! In fact, we are currently in an "opcode freeze" (no new opcodes) so that he can totally revise the core and support many of the innovations introduced by Varga, Ingalls, Gogins, and Maldonado while adding new levels of clarity and new functionality - such as plugin support, ASIO support, a new parser and much much more. (His most recent TODO list is posted in the news at cSounds.com.) For one thing, when ffitch is done, it should be easier for users to add opcodes of their own without having to recompile the entire program.
Of special note for all platforms is Steven Yi's inspired and inspiring "Blue" and "Patterns" composing and sound design environment. And also, the wonderful Csound FLTK signal processing and sound design front end "Cecilia" that has come to life in the windows version by Bill Beck and the improved Linux and osX versions by Stephan Bourgeois and Hans-Christoph Steiner.
I have forgotten to mention a ton of things like all the great new Csound editors and applets and all those free VST and DirectX plugins based on Csound Code - like he Delay Lama VST plugin and Dobson's new PVFX for Cakewalk's Project 5. What can I say? In four years, with ALL these incredible students, composers, teachers, developers on ALL thise platforms, with all these musical dreams and perspectives, what did you expect? All the new versions are great. All the new opcodes are great. All the new capabilities are great but honestly, I am thrilled by ALL the new Csound Music and the ways that Csound is being used by musicians. This is the big leap forward for Csound.
But wait one minute, have I left out all the dirt? All the name calling? All the childish bickering and mudsling? All the "my version is better than your version" stuff that you would expect from intensely competitive, young and arrogant musical programmers? Well, there has been four years of that too! (And you in the Linux community might be proud to know that most of the mud was over Linux versions of Csound!> And what has the result of those efforts been, you might ask? A lot of wasted time. A lot of deep wounds that may never heal. A lot of better versions of Csound - especially for Linux. And of course, a lot of casualties. Hundreds of newcomers and oldtimer have dropped out of the Csound community and abandoned working with Csound entirely because of all the negativity associated with it. I can't blame them. I'm getting a little tired myself of trying to teach and play music in a war zone.
(At csounds.com you can find yesterday and today's Csound News with links to the various tools and utilities that have been developed in the past 4 years. Also, you will find links to the Csound Mailing List archive where you can re-live the "War over the Future of Csound" and the vicious and childish debates over "Who Deserves to Be the Supreme Ruler of Csound.")
Q: My impression would be that the rising computational power of commodity PC platforms in recent years has benefited Csound more than the declining cost of DSP microprocessors. Would you agree, and can you comment?
A: For several years, I worked with Barry Vercoe and a team of developers (including Barry's son Scotty - I was Scotty's Csound Teacher!) on a project at Analog Devices to develop and commercialize a version of Csound built around their SHARC DSP chip. At that time, this was the way to go. For some applications it still is. Barry, in fact, continues to develop and advance such a system. And although it was a thrill to be part of that team and make a version of Csound that was fast, clean, and commercially oriented, I prefer Native Csound, public Csound, Canonical Csound. At Analog Devicest, we innovated like crazy - streamlining and restucturing the language to make it much more efficient, but all this cost some of the generality. We would come up with the best way to do things. What I love about Canonical Public Csound is that there are so many ways of working. So many of the developers, sound designers, teachers, composers have added features that we didn't have at Analog Devices. Moreover, their unique work and original designs, showed me how to a new way of doing things and helped me understand things. Even though we had built an amazing system there, a commercially viable version of Csound, I still preferred working with John ffitch, Matt Ingalls, Michael Gogins, Richard Dobson, and Gabriel Maldonado to add and improve a version of Csound that everyone could use for free.
Four years ago, real-time MIDI control did work in Csound and realtime audio was supported too, but neither worked well. At that time, no version of Csound worked as cleanly and straightforwardly as most commercial hardware and software tools. (In fact, I left most of the MIDI and Real-time Audio chapters out of "The Csound Book" because those aspect of the language were in such flux at the time that most of what we were writing was about all the little kluges and tricks you would have to use to get real-time MIDI and Real-Time Audio to work.) Today, with improved MIDI and Audio in ALL versions of Csound, with inexpensive Multi-channel USB and FireWire Interfaces, with fast PC/Macintosh laptops and cheap/fast desktops, we finally have everything we need for Csound to take the stage alongside any commercial hardware or software synthesizer - and you are starting to see a lot of this - a lot of people performing with Csound and doing interactive Sound Design, Phrase-Sampling, etc.
Q: One of the issues confronting a new user these days is that Csound continues to have a batch-oriented syntax. While front ends help, this syntax is sometimes a step backward for someone already used to object-oriented languages who'd really like use Csound directly. Could you describe the feeling within the Csound community about changing or not changing Csound's syntax?
A: I don't speak for the community. It is wonderfully rich and diverse, and that means that there are way too many desires, demands, expecations, biases, and prejudices. Then there are all the platform and OS wars to deal with too. As you might well imagine, the hackers want it one way; the composers want it another; performers, producers, sound designers want it yet another. Csound is what it is. It is easy to learn, it is easy to expand, it is easy to personalize, and it is a wonderful way to learn about synthesis, and signal processing.
I want Csound to work well. So that nothing is lost, I want it to be 100% backward compatible. At the same time, I want the real-time MIDI and real-time Audio to be comparable to that supported by any of today's commercial applications. On each hardware platform and under each operating system, I want to see Csound integrate seemlessly with other MIDI and audio applications. Today and into the distant future, I want Csound to be a free, powerful, expandible, and generally useful tool for everyone.
I want Csound to work as a plug-in/audio-unit, and I want Csound instruments to compile as plugins and audio-units. (We are getting close to this.) I can tell you that John ffitch and other key develors are currently working to make the core more solid and transparent and to make it easier to communicate with the core. There is work on the API that will allow users to simply plug in shareware/freeware/proprietary opcodes and libraries. We are very close to that even now.
For new users, there is plenty of graphically-oriented, user-friendly "Instant Csound" stuff starting to emerge because of the fact that there are so many ways today of working with Csound graphically, intuitively, transparentily, and immediately. In fact, you never need to know or care that Csound is under the hood! Cecilia was always an excellent model for this "type" of user, and it is now much improved. You can certainly expand that sytem by adding modules of your own (but you might not need to given that it is so extensive already!) Should you want to make your own graphical front-end for Csound, that is also getting easier than ever. Given the GUI capabilities in Matt Ingalls MacCsound and the GUI tools in Cycling74's Max/Msp/Jitter for Macintosh os9 and osX; and Miller Puckette'ss PD for Windows and Linux that both embed the entire Csound language as a single external object by Matt Ingalls; and given the excellent and extensive FLTK support of Gabriel Maldonado's CsoundAV for Windows, (opcodes now added to Istvan Varga's DeveloperCsound for Linux).
Csound is not C. At first glance, it looks like a programming language with all that text, numbers, and cryptic variable names. But, it doesn't take a musician very long to realize that the 500+ opcodes are simply modules that they can patch together with variables. Yes, at the lowest (and most powerful) level, Csound is text-based, but in less than an afternoon and some of my original Csound Toots or Chapter 1 from "The Csound Book," virtually anyone can figure out how to work with Csound and begin to harness it's power. If you are an intuitive, "production-oriented" musician that wants to turn knobs, make noises, mangle the noise you made by turning more knobs, etc. without having a clue, the Csound is NOT for you. Csound requires that you know something about software synthesis, digital audio, and signal processing. If you know something, and know how to use Csound, it is not too difficult for you to design Csound for Dummies Applications and Utilities which hide Csound entirely from the tweeker - I mean power-user.
Q: Many in the Linux community care quite a bit about software licensing. It appears that Csound is licensed under research-only terms that some may find too restrictive. For instance, one can fix a bug, or add a feature in their own copy, but redistribution with changes would evidently be prohibited. Is there some reason that the Csound license is set up this way, instead of having features that typify open source licenses?
A: I can tell you this, that it is not Barry Vercoe's intent for Csound to be restricted in any way. For "education and research" purposes, one can do whatever they want with Csound. Distribution seems to be one of the thorny issues. Regarding distribution, John ffitch, maintainer of the Canonical Csound at Bath University, and cSounds.com have permission from MIT and Barry Vercoe personally to distribute Csound. Furthermore, I have permission to distribute Csound on the CDROMS of "The Csound Book" and "The Csound Instrument Catalog." How can I help the developers to distribute their versions? Well, I personally pay for webspace for ALL the key developers so that they can distribute their versions of the program through cSounds.com. There really is not anyone creating free versions of Csound that is not currently able to do what they are doing or what they want to do. Selling music and samples made with Csound is also OK with Barry Vercoe and MIT. Of course, selling Csound is not. MIT has sold rights to develop commercial applications with Csound to Analog Devices and some other companies and so they have some vested interest in protecting those contracts and rights.
Still, we all wish that Csound was totally free, or that the ambiguities in the licence could be clarified. I am happy to report that Barry and I have been meeting about this very topic in the past few weeks. I have been presenting him with the viewpoints of each of the core developers - what they want to do with Csound, and what wording of the current license prevents them from taking Csound in this or that direction. During our last meeting, he contacted MIT's lawyers and we have arranged to meet with them when Barry returns from Russia and India where he is doing Media Lab work and Csound work. Hopefully these meetings will result in a new licence or some new wording that will encourage future developers in their efforts to improve and extend the language.
Q: Csound seems like a very nice interdisciplinary tool for students, bridging across multiple subjects like music, sound, psychoacoustics, and DSP. What have been some of your best experiences with Csound in the University setting?
A: Csound is the ultimate educational platform for students of Computer Music. In The Csound Book, every bit of synthesis and signal processing theory are supported and illustrated by complete and fully working Csound instruments that can be edited and expanded and fully explored by the student. I have been teaching Csound to undergraduate Music Synthesis and Music Production and Engineering Majors at the Berklee College of Music for 18 years. For the past four years, I have been teaching Csound to graduate students at NYU. I have given Csound workshops and seminars in Eastern Europe, Western Europe, and Southeast Asia. I use Csound in my DSP classes both at Berklee and NYU and in my Max/MSP classes as well. Currently, we are developing a set of Psychoacoustic tools for Music Therapy students at Berklee and I am about to introduce a whole new area at cSounds.com developed by my son Adam (a student of Scotty Vercoe!)
Csound has always been an excellent tool for teaching and learning synthesis, acoustics, and signal processing. The Csound Book reveals virtually all the industry secrets. When my students get Csound into a major motion pictures or major telivision programs because of the Csound gigs with Media Ventures or Machinehead; when my students get Csound into Video Games because of their Csound gigs with Lucas Arts, and Dreamworks; when my students do Csound work for Rock Stars like Trent Reznor, Aphex Twin (Richard James), DJ Spooky; when my students get jobs in Add Agencies, Jingle Houses, and Recording Studios and Csound gets into national ads with voice talents like Jamie Lee Curtis; when my students get gigs at Cakewalk, MOTU and other software companies because they know and work with Csound; when my students publish thier own Computer Music Books in Korea; when Csound compositions by my students win national and international competitions; when Csound helps my students get into graduate schools; when my students find ways a making Csound work in their musical toolkit, these are some of the most gratifying things about teaching Csound.
Hearing that computer music professors and students from all over the world are using Csound and using The Csound Book is really great, because Csound is really great - and getting better all the time. It is gratifying to know that my work has been helpful and inspiring to them. Max Mathews, the father of computer music is a good friend and mentor to both Barry Vercoe and I. His MusicV program inspired Barry to develop Csound and his book "The Technology of Computer Music" inspired me to write "The Csound Book." Barry's son Scotty was my student. My oldest son Adam, a Music Therapy major at Berklee, was Scotty Vercoe's student. Today Adam Boulanger is building tools for his own Psychoacoustic research in Csound and through his research tools, introducing Csound to the Music Therapy community. I guess I am most psyched about the fact that the future of Csound is in the hands of some great students including Barry Vercoe's and my own very talented sons.
In the year I was born, 1956, Max Mathews (the father of computer music) had a dream and began to realize it in his MusicN languages. He passed the torch to Barry Vercoe and their light inspired a nineteen year old composer and electronic musician named Richard Boulanger. I am trying to pass along what I have learned from them and what I have learned from my brilliant students and colleagues. I hope it helps, and I hope that something I have said in this interview inspires some of your readers to check out Csound Today.
RESOURCES
Csound web site
http://csounds.com
Dave Phillips Article:
http://www.linuxjournal.com/article.php?sid=3187
"The Csound Book: Perspectives in Software Synthesis, Sound Design,
Signal Processing, and Programming."
Edited by Richard Boulanger
The MIT Press
Cambridge, Massachusetts
London, England
ISBN 0-262-52261-6