
|
Table of Contents:
|
||||
Editor: Michael Orr
Technical Editor: Heather Stern
Senior Contributing Editor: Jim Dennis
Contributing Editors: Ben Okopnik, Dan Wilder, Don Marti
|
TWDT 1 (gzipped text file) TWDT 2 (HTML file) are files containing the entire issue: one in text format, one in HTML. They are provided strictly as a way to save the contents as one file for later printing in the format of your choice; there is no guarantee of working links in the HTML version. | |||
![[tm]](../gx/tm.gif) ,
http://www.linuxgazette.com/ ,
http://www.linuxgazette.com/This page maintained by the Editor of Linux Gazette, gazette@ssc.com
Copyright © 1996-2001 Specialized Systems Consultants, Inc. | |||
 The Mailbag
The Mailbag
Send tech-support questions, answers and article ideas to The Answer Gang <linux-questions-only@ssc.com>. Other mail (including questions or comments about the Gazette itself) should go to <gazette@ssc.com>. All material sent to either of these addresses will be considered for publication in the next issue. Please send answers to the original querent too, so that s/he can get the answer without waiting for the next issue.
Unanswered questions might appear here. Questions with answers -- or answers only -- appear in The Answer Gang, 2-Cent Tips, or here, depending on their content. There is no guarantee that questions will ever be answered, especially if not related to Linux.
Before asking a question, please check the Linux Gazette FAQ to see if it has been answered there.
 Arcane information ...
Arcane information ...Bryan Anderson wrote an article in August 2001 Linux Gazette titled 'Make your Virtual Console Log In Automatically'.
Many years ago, before the Web when terminals mattered a lot more, I spent many hours combing through kernel code and experimenting to figure out process groups, sessions, controlling terminals, job control, SIGINT, SIGHUP, and the like. I could write a long article on it, but I think it's really arcane information.
Thu, 2 Aug 2001 16:39:28 -0700
brad harder (bharder from methodlogic.net)
I'd be interested to read what Bryan has to say about this subject ...
-bch
Thu, 16 Aug 2001 13:27:50 +0200
Yann Droneaud (ydroneaud from meuh.eu.org)
Hi,
I read the article written by Bryan Anderson in August 2001 Linux Gazette titled 'Make your Virtual Console Log In Automatically'. The last section about process groups and controlling terminal was too short for me.
I would be happy if Bryan could write a technical article about this subject as it's suggested by him and the editor. I'm wondering his knowledge could help me.
PS: my currently knowledge is based on a approxmilty reading of bash source code and the GNU libc manual (info).
-- Yann Droneaud
PortalsWhat combination of open source software should be used to create a portal site? How could a beginner build and test such a site?
A handful of the Answer Gang are just starting to give him links to some related software, but an article from someone out there who has already had the experience would be even better.
Migrating to SAGUI work as technology consultant for a small University Centre in the South of Brazil ... we have migrated all of our academic/administrative system into Free Software, developing the SAGU system.
BTW, I am a guest speaker at the Annual Linux Showcase, where I will be presenting our SAGU system.
Well, let me know if you like the idea and I will produce an article.
Thanks, Cesar, we'd love to see your article. It falls solidly into the "real life experiences" category defined in our author guidelines. You should look there for the upcoming deadlines, and submit to gazette@ssc.com.
You may find also interesting we host a "Source Forge" site at "http://codigoaberto.org.br" where we have more than 80 hosted projects, from people all over Brazil.
Cesar Brod
Univates/Brod Tecnologia
Gentle Readers: If you have broad reaching projects that you think make Linux fun and more useful, we encourage you to consider submitting an arttcle too!
Re: MistakeThis is an exchange regarding CUP
Michael has taught the compiler course at Washington Univeersity, and
programming languages is one of his areas of study.
On Thu, 28 Jun 2001 18:16:59 +0100 Xavier wrote:
I just look at your issue 41 (I know that is not really recent ...) but in the article of Christopher Lopes which is talking about CUP, there is a mistake...
I tested it and I see that it didn't walk correctly for all the cases. In fact it is necessary to put a greater priority to the operator ' - ' if not, we have 8-6+9 = -7 because your parsor realizes initially (6+9 = 15) and after (8-15= -7). To solve this problem it is enough to create a state between expr and factor which will represent the fact that the operator - has priority than it +.
Cordially.
Xavier Prat.
On Wed, Aug 01, 2001 at 05:56:21PM -0500, Michael P. Plezbert wrote:
I just couldn't let this slip by.
![]()
You do NOT want to give the minus operator a greater priority than the
plus operator, because then expressions like a+b-c would parse as a+(b-c),
which generally is not what you want. (Algebraically, plus and minus are
usually given the same priority, so a+b-c means (a+b)-c.)
In fact, giving the minus operator a higher priority in the CUP file (using CUP's priority capability) will not change anything given the grammar as written in the original article, since the grammar is unambiguous with regard to plus and minus.
The problem is that the lines in the grammar
expr ::= factor PLUS expr
| factor MINUS expr
cause the plus and minus operators to be right-associative, when we want them to be left-associative.
The fix is to changes the lines to be
expr ::= expr PLUS factor
| expr MINUS factor
This will make the grammar associate the plus and minus operators in the usual way.
(This may have been what the author of the previous mail meant, but the text was unclear and the link to the CUP file was broken.)
Michael
That broken link had been my fault (sorry) but it was fixed immediately when you let us know. Thanks! -- Heather
Michael is right... The fix is just to transform the rules of expr for PLUS and MINUS become left-associative. Thing which I had made in my preceding fix, but it's true that to give a higher priority to MINUS is, in fact, totaly useless...
thanks.
Xavier PRAT.
Re: Mistake ...Eh folks !!
Why don't you just remove all the factor productions (which is clearly school boy junk ...) and leave nothing between <expressions> and <terms> so that the precedence directives can work freely, and there will be no problem :
ex.
precedence left MINUS, PLUS; precedence left TIMES, DIVIDE;
and
expr ::= term
| expr MINUS expr
| expr PLUS expr
| expr TIMES expr
| expr DIVIDE expr
We needed a bit more clarity, originally we weren't sure what he was replying to:
Generally the examples given along with developement packages or with teaching-manuals, should be merely considered as simple hints and if used 'as-is', extreme care should be taken ...
In the case of modern LALR parser generators with the feature of precedence-directives :
- the factor-type productions often present in examples (in grammars with expression-productions), are error prone and uselessly over-clobber grammars.
- thus factor-type productions should simply be left out so that precedence rules can work freely as expected.
Enjoy
Waldemar
Thank you everyoneOn Fri, Aug 10, 2001 at 01:34:54PM -0700, Lindsey Seaton wrote:
Thank you everyone who helped to answer my question. The web page that was linked in one of the e-mails was very helpful and added to my "favorites" list for future referance.
Thanks for letting us know. And when you know a bit more about Linux and are able to answer this question for somebody else, please do so. That's what keeps the Linux community active.
Learning Perl, part 5 (LG #69)I was reading your article in the Linux Gazette about programming perl and I have a little problem in a simple script. This is the script that should open /var/log/messages and search for some text:
#!/usr/bin/perl -w
use strict
open(MESS, "</var/log/messages") or die "Cannot open file: $!\n";
while(<MESS>) {
print "$_\n" if /(fail|terminat(ed|ing)|no)/i;
}
close MESS;
when I run the script the result is the following:
$ ./logs.pl
syntax error at ./logs.pl line 4, near ") or"
Execution of ./logs.pl aborted due to compilation errors.
Do you have a clue about what's going on?
I have a RedHat Linux with perl 5.6.0
I believe I've actually mentioned this type of error in one of the articles. It's a very deceptive one... and yet shared by all languages that ignore whitespace, due to the way the parser has to look at the code.
Look at line 4 carefully. Look at it again. Can't find anything wrong? That's because there isn't anything. Instead, take a look at the previous line of code, line 2 - it's missing a semicolon at the end! When that happens, Perl figures that you simply continued your statement further down - so, what it sees is
use strict open(MESS, "</var/log/messages")
at which point it realizes "Uh-oh. We've gone past anything that looks like valid syntax for the 'use' function - PANIC TIME!"
The lack of a terminator on a previous line is always an error on the current line.
Learning Perl: thank youHey,
Just wanted to drop a quick line and say thank you for your Learning Perl series in Linux Gazette. I very much enjoyed your writing style, technical depth, and approach ... I picked up a lot of useful tips, and I've been using Perl for quite a while.
Keep up the excellent work.
-- Walt Stoneburner
Mirror searchesPer the request of one of our mirrors in Germany, I have added a provision for our mirror sites who want to run their own search engine. Starting with this issue, the Search link on the home page and the TOC page has changed from "Search" to "Search (www.linuxgazette.com)".
Mirrors with their own search engine may replace the text between
<!-- *** BEGIN mirror site search link *** -->
and
<!-- *** END mirror site search link *** -->
with a link to "(SITE.COM mirror)" on the TOC page, and "Search (SITE.COM mirror)" on the home page.

|
Contents: |
Submitters, send your News Bytes items in PLAIN TEXT format. Other formats may be rejected without reading. You have been warned! A one- or two-paragraph summary plus URL gets you a better announcement than an entire press release.
 September 2001 Linux Journal
September 2001 Linux Journal

The September issue of Linux Journal is on newsstands now. This issue focuses on Security. Click here to view the table of contents, or here to subscribe.
All articles through December 1999 are available for
public reading at
http://www.linuxjournal.com/lj-issues/mags.html.
Recent articles are available on-line for subscribers only at
http://interactive.linuxjournal.com/.
September/October 2001 Embedded Linux Journal

Click
here
to view the table of contents. US residents can subscribe to ELJ for free; just
click here.
Paid subscriptions outside the US are also available; click on the above link
for more information.
Debian
SuSE
Upcoming conferences and events
Listings courtesy Linux Journal. See LJ's Events page for the latest goings-on.
Sklyarov, DMCA, FTAA update
As LG went to press, several events unfolded in the Sklyarov/DMCA case:
The Electronic Frontier Foundation (EFF) is speaking out against industry attempts to get controversial provisions from the US Digital Millenium Copyright Act (DMCA) put into the Free Trade of the Americas (FTAA) agreement. (The FTAA is a still-unfinished treaty that would create a free-trade zone covering North and South America.) "The FTAA organization is considering treaty language that mandates nations pass anti-circumvention provisions similar to the DMCA, except the FTAA treaty grants even greater control to publishers than the DMCA." If you feel strongly about this, the EFF invites you to try to change the situation and provides suggestions for the sort of letters you could write.
Because LG is a monthly publication, we cannot adequately address all the developments in the DMCA controversy. We refer you instead to the Linux Weekly News editorials, the EFF home page, and the various activist sites such as nodmca.org and freesklyarov.org.
LWN's August 30 editorial raises the irony of Dmitry possibly getting a longer prison sentance than "mere armed robbers, rapists and child molesters". It states, "One way or another, we are now seeing the degree of repression that the US is willing to apply to ensure that certain kinds of software are not written.... It takes very little imagination to picture a future where the general-purpose computer has been replaced by a 'trusted computing platform', and systems which do not 'seal data within domains' are treated as 'circumvention devices'. At what point, exactly, does Linux become an illegal device under the DMCA? In a world where programmers face 25-year sentences for code that was legal where they wrote it, this vision should not be seen as overly paranoid."
An older LWN editorial discusses attempts in Canada to insert DMCA-like provisions into its copyright law.
Meanwhile, Slashdot reports on an
NPR article
saying that many US radio stations are pulling the plug on their webcasting
"due to concerns about advertising, royalties and the DMCA". Slashdot then
reports on a
CNN article
about a study saying "people don't and won't purchase heavily restricted music
online at higher prices for a less useful item." Slashdot then adds,
"This is apparently a revelation to the music industry."
![]()
Total Impact and Terra Soft Solutions Partner to Offer
PowerPC Linux Products
Total Impact has also just announced availability of its new Centricity line of Render Engines � beta tests are "creating anticipation that Centricity systems will revolutionize high performance computing with their small size, high processing speeds, low power requirements and ease of use".
New I/O Module
MEN Micro's new PC-MIP mezzanine card featuring a 48-bit TTL I/O interface, may allow embedded system designers to quickly implement basic digital I/O without an involved development process. For simple digital I/O, such as a control switch or an actuator, the new PC� MIP card can be easily added to a single-board-computer (SBC) or a PC� MIP carrier card, assuring a rapid completion of the system's development. Through the MEN Driver Interface System (MDIS), the P13 is supported by drivers for a wide range of operating systems, including VxWorks, OS-9, WindowsNT and Linux.
New Keyspan USB Products at Linux World
Keyspan has announced new versions of its USB PDA Adapter and its High Speed USB Serial Adapter. In addition to "off-the shelf" support for Linux 2.4, Keyspan's Serial-to-USB Adapters also support Windows 98, Windows Me and Windows 2000, as well as Mac OS 8.6 or higher. Beta drivers for Mac OS X are also available.
Alabanza Gets Smarts!
Sair Linux and GNU Newsletter #9
SAIR Linux and GNU Certification's quarterly newsletter, SAIR Linux and GNews issue 9, is available for you to view online.
IBM
IBM has announced the new IBM "Start Now" Solutions for e-business, a family of offerings to help small and medium businesses (SMB) rapidly implement powerful, cost-effective, e-business solutions. The eight Start Now Solutions, including three Linux-based solutions, "fulfill the requirements of e-business--from initial Internet access, through e-mail, research and information, Web site management, simple and complex e-commerce, business intelligence, integrated activities and new business opportunities". For more information on IBM Start Now solutions, visit http://www.ibm.com/software/smb.
Book "Advanced Linux 3D Graphics Programming" available
The book "Advanced Linux 3D Graphics Programming" is now available for purchase. It is the follow-up volume to the first book "Linux 3D Graphics Programming". This second volume provides programmers who are experienced in both Linux and fundamental 3D graphics concepts with a well-rounded perspective on 3D theory and practice within the context of programming larger interactive 3D applications such as games. It covers such topics as texture and light mapping, creating compatible morph targets in Blender, creating and importing IK animations into a 3D engine, BSP trees (node and leaf based), portals, level editing, particle systems, collision detection, digital sound, content creation systems, and more. A table of contents is viewable online and if you like what you see, purchase online.
unixboulevard.com
UnixBoulevard.com is a free and upcoming site designed to be a choice web location for those individuals and organizations that use, manage Unix based servers or Networks. The site provides product and technical support information as well as a forum for UNIX community members to interact.
CDW is offering free VXA media for Linux
GX Technology Uses Linux NetworX Cluster System
in Oil and Gas Exploration
Linux NetworX, a provider of powerful and easy-to-manage cluster computing solutions, announced today that seismic imaging solutions company GX Technology has purchased an 84-processor Evolocity computer cluster to be used in its oil and gas exploration efforts. This is the third cluster computer system provided to GX Technology by Linux NetworX.
Linux NetworX optimized the Evolocity cluster to work with GX Technology's seismic imaging applications to perform processes such as wave equation and Kirchhoff pre-stack depth migration and prestack time migration. The 42-node Evolocity system includes 84 1.2 GHz AMD Athlon MP processors, with each node containing 1.5 GB of memory, and two 10/100 Ethernet networks for redundancy. GX Technology also utilizes the Linux NetworX ClusterWorX management software tools, and signed an on-going service agreement to ensure system stability.
Linux Links
Linux project in Mexican schools (Red Escolar) fails, largely due to "winmodem" issues it seems. More positively, Linux seems to be finding a role in a Colorado school district. News courtesy Slashdot.
CanadaComputes.com have a round up of the Linux web browsers currently available.
Linux Journal web articles:
Suite101.com have added a new Linux site aimed at explaining to Windows users what it might be like if they changed to Linux.
The Register have reported that several Red Hat 6.2 systems with default installation were cracked in 72 hours during a security research project that intentionally left them online for intruders to find.
Evaluation of Windows XP beta compared to Linux Mandrake 8.0 from the point of view of usability and aesthetics. The review says Windows is getting better than it used to be; Microsoft is learning some of Linux's tricks.
RPM Search page on the User Friendly site.
Slashdot had a recent Slashdot talkback thread on which is the best Linux distribution for a newbie.
The State of Corporate IT: A case for Linux.
"By many accounts, the largest cost of ownership increases that
corporations have faced have been licensing related. As NT has become a
mainstay, licensing terms have become more specific and more expensive."
This story traces a 7,000-employee company that switched from Unix/Novell
to NT for "ease of administration and a lower cost of ownership, but years
into the transition, administering and licensing costs soared....
While the previous Unix and Novell platforms had handled file, print and mail
servers on a single server, NT now needed one machine for each service plus a
dedicated backup for each.....
Red Hat brought a single Pentium class system for a site visit and thanks to
the early legwork their engineers had done, were able to integrate the box into
the network and take over all file and print server requests for one busy
segment within four hours. The system ran for the next 10 business days without
any downtime, something NT machines had not been able to do very often....
Red Hat had proven to be a helpful ally. Instead of trying to push a
whole-scale replacement of the infrastructure, they had worked to supplement
it.... Some months later, with the market still soft and the bottom line
increasingly important to shareholders, the team feels they made the right
decision."
Courtesy Slashdot.
The Los Angeles Times have a science fiction story about a future world in which Windows is everywhere, causing worldwide catastrophe. Courtesy Slashdot.
Loki
TimeGate Studios, Inc. and Loki Software are excited to announce that the demo for Kohan: Immortal Sovereigns on the Linux platform is now available for free download at http://www.lokigames.com/products/demos.php3 For more information, please visit the official game site. Pre-orders can be placed from the Loki webstore.
No Starch Press and Loki Software have announced the launch of the complete and authoritative guide to developing games for Linux. PROGRAMMING LINUX GAMES: LEARN TO WRITE THE GAMES LINUX PEOPLE PLAY (August 2001, 1-886411-49-2, $39.95, paperback, 432 pp., http://www.nostarch.com/?plg) guides readers through important Linux development tools and gaming APIs, with a special focus on Simple DirectMedia Layer (SDL). Written by the gaming masters at Loki Software, this book is the ultimate resource for Linux game developers. Available in bookstores, from Loki Software (http://www.lokigames.com/orders), or from No Starch Press (1-800-420-7240, http://www.nostarch.com).
eVe Visual Search Toolkit for Linux
eVision is excited to announce the release of version 2.1 public beta of the eVe visual search Java-based SDK for Linux. The toolkit lets Linux developers create search applications that use images and visual similarity rather than keywords and text. The user selects a sample query image or partial image, then the search engine finds and ranks other images that are visually similar with respect to the objects in the image and attributes such as color, texture, shape and 3D shading. This technology can be applied to image content, video content, audio content and any other digital pattern. You can sign up to download a free 500 image limited version of the SDK at http://www.evisionglobal.com/developers/sdk/
Great Bridge WebSuite for Developers
Great Bridge, a provider of commercial service and support for the open source database PostgreSQL, has announced this morning an open source application development platform that uses the world's most advanced open source tools. Great Bridge WebSuite is an integrated open source platform that combines the PostgreSQL database, PHP scripting language and Apache Web server for building high-performance Web-based applications.
Free APStripFiles Utility
Appligent, Inc. is offering a new utility free of charge. APStripFiles is a command line application that removes attached or embedded files from PDF documents. It enables you to protect your systems from malicious unwanted PDF file attachments.
APStripFiles for AIX, HP-UX, Sun Solaris and Red Hat Linux can be downloaded free from,, http://www.appligent.com/newpages/freeSoftware_Unix.html
 The Answer Gang
The Answer Gang

There is no guarantee that your questions here will ever be answered. Readers at confidential sites must provide permission to publish. However, you can be published anonymously - just let us know!
 Greetings from Heather SternScary disk error
Greetings from Heather SternScary disk errorFrom Mike Orr
Answered By Ben Okopnik
![]() Just got a disturbing disk error. It was on my 486 laptop, which I've
only used for reading and writing text files on the past few years because
of its limited capacity (16 MB RAM, 512 K HD).
Just got a disturbing disk error. It was on my 486 laptop, which I've
only used for reading and writing text files on the past few years because
of its limited capacity (16 MB RAM, 512 K HD).
1) I was in vi, and it caught a SEGV. Fortunately, it was able save its recovery file. I restarted vi, recovered the file, saved it, deleted the recovery file and went on typing. Then,
[Ben] Could be memory, could be HD...
![]() 2) I got an oops. Something about paging. I figured, common enough oops,
2) I got an oops. Something about paging. I figured, common enough oops,
![]() even though it's never happened on that computer, so I pulled out the power
cable for a second and rebooted. (The battery had long ago stopped holding
any charge.) Linux found that the HD had been mounted uncleanly (no duh)
and started fsck. Fsck found two deleted files with zero dtime and fixed
them. I was glad I had saved the file after recovering it since I'd
deleted the recovery file. Then--
even though it's never happened on that computer, so I pulled out the power
cable for a second and rebooted. (The battery had long ago stopped holding
any charge.) Linux found that the HD had been mounted uncleanly (no duh)
and started fsck. Fsck found two deleted files with zero dtime and fixed
them. I was glad I had saved the file after recovering it since I'd
deleted the recovery file. Then--
3) "Kernel panic: free list corrupted". I rebooted. Again the same error. What do you run when fsck doesn't work?? Is all my data gone bye-bye? Not that it was that much, and I was about to blast away the current (Debian) installation anyway and practice installing Rock Linux. (If, of course, the disk is good enough to be reformattable.)
4) A happy ending. I rebooted again to make sure I had the panic message right, and this time fsck completed and I got a login prompt. Quickly I tarred up my data and copied it onto a floppy.
I wonder if this will make Wacky Topic of the Month.
![]() Doesn't fsck automatically restart sometimes? I know I've seen it do
this, although the last time was early in the kernel 2.2 days. Is it an
ex-feature? Or maybe Debian did it with a 'while' loop or something.
Doesn't fsck automatically restart sometimes? I know I've seen it do
this, although the last time was early in the kernel 2.2 days. Is it an
ex-feature? Or maybe Debian did it with a 'while' loop or something.
![]() Of course, you can't interrupt an oops with a Ctrl-C. When an oops
happens, the machine halts and must be reset.
Of course, you can't interrupt an oops with a Ctrl-C. When an oops
happens, the machine halts and must be reset.
![]() Sorry, I wasn't thinking clearly. An oops is most likely bad memory, a
bad disk or cosmic rays. A kernel panic (in my experience) is more likely
to be a programming, configuration or environment issue. In either case, the
machine halts and you can't recover except by resetting it. What is
curious is, is there a certain moment during disk activity where a SEGV
or oops would leave the filesystem in a "free list corrupted" state?
Intuitively, there must be.
Sorry, I wasn't thinking clearly. An oops is most likely bad memory, a
bad disk or cosmic rays. A kernel panic (in my experience) is more likely
to be a programming, configuration or environment issue. In either case, the
machine halts and you can't recover except by resetting it. What is
curious is, is there a certain moment during disk activity where a SEGV
or oops would leave the filesystem in a "free list corrupted" state?
Intuitively, there must be.
![]() The next question is, is it possible to
retrieve the data after such an error (short of running a sector-by-sector
analysis)? Apparently there is, and fsck does it, although it takes a
couple runs to finish the repair.
The next question is, is it possible to
retrieve the data after such an error (short of running a sector-by-sector
analysis)? Apparently there is, and fsck does it, although it takes a
couple runs to finish the repair.
![]() Too bad fsck can't somehow avoid causing a kernel panic or that the kernel
can't figure out the situation enough to provide a more reassuring error
message.
Too bad fsck can't somehow avoid causing a kernel panic or that the kernel
can't figure out the situation enough to provide a more reassuring error
message.
![]() The worst fsck case Jim Dennis ever had against required him to run
fsck 6 times, but it did eventually succeed in cleaning up the mess
he had made. (He had told his video controller to use the address
range which the hard disk controller actually owned. Typos can be
really bad for you at that level.) The moral here is, if at first
fsck does not succeed, don't give up all hope. You may prefer to
reformat afterwards anyway, but you should get a decent chance to
rescue your important data first. -- Heather
The worst fsck case Jim Dennis ever had against required him to run
fsck 6 times, but it did eventually succeed in cleaning up the mess
he had made. (He had told his video controller to use the address
range which the hard disk controller actually owned. Typos can be
really bad for you at that level.) The moral here is, if at first
fsck does not succeed, don't give up all hope. You may prefer to
reformat afterwards anyway, but you should get a decent chance to
rescue your important data first. -- Heather
question please please please answerFrom Lindsey Seaton
Answered By Frank Rodolf, madeline, Thomas Adam
![]() Excuse me. I have a question
Excuse me. I have a question
As a computer project, I was assigned to get on the computer and find out what linux is and what it is used for. I don't know if it's an orginization or if it's part of HTML script or anything. Please e-mail me back with the answer please. I just know so little about computers and one name can mean so many different things on the internet. I had only just now I had been spelling it wrong (linex) until I found out it was spelled linux.
What I can do, is send you to the list of Frequently Asked Questions (FAQ). The question you ask is the very first question in there. You can find it here:
http://www.linuxdoc.org/FAQ/Linux-FAQ/index.html
![]() Thank you for your help.
Thank you for your help.
Like Windows and Mac OS, Linux is an operating system, which is a program that is in charge of organizing and running everything on your computer. Here is a definition of operating system: http://www.webopedia.com/TERM/o/operating_system.html
Unlike Windows and Mac OS, Linux is free, and the programming code that was used to create it is available to everyone. As a result, there are many versions of linux (such as Red Hat, Gnome, and SuSE) which are somewhat different but with the same foundation (called a "kernel"--this kernel is updated every so often by the creator of Linux, Linus Torvalds, and company). Linux is usually the operating system of choice for computer programmers and scientists because it is very stable and well-designed (not crashing randomly and often as Windows tends to do).
I hope this helps.
Madeline
Many people also find Linux and other Unix derivatives more flexible than other operating systems.
Firstly, your question is far too broad. There have been numerous books written about the history and use of Linux, and it is beyond the scope of my knowledge to tell you everything.
Considering that Thomas is "The Weekend Mechanic" and has written several articles for the Linux Gazette over the years, that's saying something significant. -- Heather
Linux was created by scratch in ~1991, by Linus Torvalds, a very gifted person for Finland. His goal was to create a Unix like operating system. Thus, he was assisted by numerous loosly-knit programmers over the world, to produce the kernel, the "heart" of the operating system. Essentially, this is what "Linux" refers to.
Linux is an operating system, and is an alternative to the de facto operating system "MS-Windows". Linux is a Unix-like operating system (as I have already said). There are many different "distibutions" of Linux, which use different means of distributing data, either in RPM format, .tgz format etc.
If you are interested, you could try Linux out (by using a floppy based distibution, such as HAL91 available from the following:
http://www.itm.tu-clausthal.de/~perle/hal91
and then you can run Linux off a floppy disk. Bear in mind however, that this will offer no GUI frontend.
I hope this has answered a little of your question, even if it is brief.
Piercing the VeilAnswered By Jim Dennis
Problem: You're using a system at work that's on an internal (non-routable) IP address (as per RFC191, or that's behind a set of proxy servers or IP masquerading routers. You want to work from home, but you can't get into your system.
WARNING: This hack may be a violation of the usage policies either of the networks involved! I'm describing how to use the tool, you assume all responsibility for HOW you use it. (In my case I'm the one who sets the policy; this is just a convenient trick until I get around to setting up a proper FreeS/WAN IPSec gateway).
Let's assume that you have a Linux desktop or server "inside" and another one "at home" (obviously this trick will work regardless of where "inside" and "at home" really are). Let's also assume that you have OpenSSH installed at both ends. (It should work with any version of SSH/Unix and possibly with some Windows or other clients, I don't know).
As root on your internal machine, issue the following command:
ssh -f -R $SOMEPORT:localhost:22 $YOURSELF@$HOME 'while :; do sleep 86400; done'
... this will authenticate you as $YOURSELF on your machine, $HOME and will will forward tcp traffic to $SOMEPORT on $HOME back trough the tunnel to port 22 (the SSH daemon) on localhost (your "inside" machine at work). You could forward the traffic to any other port, such as telnet, but that would involve configuring your "inside" machine to allow telnet and (to be prudent) configuring its TCP wrappers, ipchains etc, to disabled all telnet that didn't come through (one of) our tunnels.
The fluff on the end is just a command for ssh to run, it will loop around forever (the : shell built-in command is always "true") sleeping for a whole day (86400 seconds) at a time. The -f causes this whole command to fork into the background (becomming a daemon) after performing any authentication (allowing you to enter passwords, if you like).
To use this tunnel (later, say from home) you'd log into $HOME as yourself (or any other user!) and run a command like:
ssh -p $SOMEPORT $WORKSELF@localhost ...
or:
ssh -p $SOMEPORT -l $WORKSELF localhost
... Notice that you use the -p to force the ssh client to connect to your arbitrarily chosen port (I use 1022, 2022, etc. since they end in "22" which is the IANA recognized ssh protocol port). The -l (login as) or the form $WORKSELF@ are equivalent. Note that you user name at work needn't match your name at home, but you must use the "REMOTE" username to connect to the forwarded port.
That bears repeating since it looks weird! You have to use the login name for the remote system even though the command looks like your connecting to the local host (your connection is being FORWARDED).
If you use these commands you can log into a shell and work interactively. You can add additional arguments to execute non-interactive commands, you can set up your ssh keys (ssh-keygen, append $HOME/~/.ssh/identity.pub to $WORK~/.ssh/authorized_keys) so that you can gain access without typing your password (though you should configure your ssh key with a passphrase and use ssh-agent to manage that for you; then you only have to enter you passphrase once per login session to access all of your ssh keyed accounts).
You can also copy files over this tunnel using the scp command like so:
scp -P $SOMEPORT $WORKSELF@localhost:$SOURCEPATH $TARGET
... not that this is an uppercase "P" to select the port, a niggling difference between the syntax of the ssh client and that of the scp utility. Of course this can be done in either direction; this example copies a remote file to a local directory or filename, we're reverse the arguments to copy a local file to the remote system.
As I hinted before, you are actually double encrypting this session. You tunnel to the remote system is encrypted, and in this case the connections coming back are to a copy of the sshd back on your originating machine; which does it's encryption anyway. However, the double encryption doesn't cost enough CPU time to be worth installing a non-encrypting telnet or rsh and configuring it to only respond to requests "from" localhost (from the tunnels).
One important limitation of this technique: Only one remote user/session can connect through this tunnel at a time. Of course you can set up multiple tunnels to handle multiple connections.
This is all in the man pages, and there are many references on the net to using ssh port forwarding, but finding an example of this simple trick was surprisingly difficult, and it is a bit tricky to "grok" which arguments go where. Hopefully you can follow this recipe to pierce the corporate (firewall) veil and get more work done. Just be sure you clear it with your local network and system administrators!
Every time Modem Hangup When Connect time 3.3 min.From sunge
Answered By Karl-Heinz Herrmann, Frank Rodolf
Dear TAG members,
When I use ppp-on script connect to my ISP, almost EVERY time the modem will hangup when the
connect time is 3.3 minutes:
$tail -n 10 /var/log/messages ... Jul 15 19:37:37 localhost pppd[1703]: Hangup (SIGHUP) Jul 15 19:37:37 localhost pppd[1703]: Modem hangup Jul 15 19:37:37 localhost pppd[1703]: Connection terminated.
Jul 15 19:37:37 localhost pppd[1703]: Connect time 3.3 minutes. Jul 15 19:37:37 localhost pppd[1703]: Sent 4656 bytes, received 6655 bytes. Jul 15 19:37:37 localhost pppd[1703]: Exit. $
But if I use Kppp, modem will NOT hangup.
Thank you.
Regrads,
--
sunge
I guess your startup causes about 0.3min traffic after which no further traffic occurs and your timeout with ppp-on is set to 3 minutes. kppp may have that set to a longer time.
The init string is something like AT ..... Sx=3 I'm not sure anymore, but the register number x was something like 6 or 9... see the modem manual for details.
K.-H.
Just a small addition to what Karl-Heinz wrote.
The register (at least in a standard Hayes compatible register set) would be number 19 and the number after the = does indeed indicate the number of minutes of inactivity before disconnecting.
Grtz,
Frank
BashFrom Chris Twinn
Answered By Ben Okopnik
![]() I am trying to write a little bash script to update the crontab on
RH7. Problem is that when I put
I am trying to write a little bash script to update the crontab on
RH7. Problem is that when I put
linetext = $1" * * * * " root bash /etc/cron.hourly/myscript or
![]() linetext=$1" * * * * " root bash /etc/cron.hourly/myscript
linetext=$1" * * * * " root bash /etc/cron.hourly/myscript
I get back "2 configure ipchaser 2 configure ipchaser" which is an ls of that current directory fronted by the number 2 in my variable at each point of the star's.
linetext=$1' * * * * root bash /etc/cron.hourly/myscript' linetext="$1 * * * * root bash /etc/cron.hourly/myscript"
Either one of the above would result in "$linetext" containing
2 * * * * root bash /etc/cron.hourly/myscript
(this assumes that "$1" contains '2'.) Note that you have to echo it as
echo "$linetext"
not
echo $linetext
Otherwise, "bash" will still interpret those '*'s.
... he cheerfully reported back, his problem is solved ...
![]() Wicked.
Wicked.
![]() Many Many Thanks.
Many Many Thanks.
questionFrom Anonymous
Answered By Mike Orr, Nick Moffitt
![]() I have a question about the "finger" option on telnet. I know that you ccan
find out when someone has logged in by entering "finger name" But I was
wondering if it possible to find out who has tried to finger your e-mail
account??
I have a question about the "finger" option on telnet. I know that you ccan
find out when someone has logged in by entering "finger name" But I was
wondering if it possible to find out who has tried to finger your e-mail
account??
Please keep my name anonymous.
If you are the sysadmin, you can run "fingerd" with the "-l" option to log incoming requests; see "man fingerd". Otherwise, if you have Unix progamming experience, it may be possible to write a script that logs information about the requests you get. If you're merely concerned about security, the correct answer is to turn off the "fingerd" daemon or read the "finger" and "fingerd" manpages to learn how to limit what information your computer is revealing about you and about itself. However, you have some misconceptions about the nature of "finger" which we should also address.
The long answer:
"finger" and "telnet" are two distinct Internet services. "http" (WWW) and "smtp" (sending e-mail) are two other Internet services. Each service is completely independent of the others.
Depending on the command-line options given and the cooperation of the remote site, "finger user@host" may tell you:
(1) BASIC USER INFORMATION: the user's login name, real name, terminal name and write status, idle time, login time, office location and office phone number.
(2) EXTENDED USER INFORMATION: home directory, home phone number, login shell, mail status (whether they have any mail or any unread mail), and the contents of their "~/.plan" and "~/.project" and "~/.forward" files.
(3) SERVER INFORMATION: a "Welcome to ..." banner which also shows some informations (e.g. uptime, operat�ing system name and release)--similar to what the "uname -a" and "uptime" commands reveal on the remote system.
Normally, ".plan", ".project" and ".forward" are regular text files. ".plan" is normally a note about your general work, ".project" is a note about the status of your current project(s), and ".forward" shows whether your incoming mail is being forwarded somewhere else or whether you're using a mail filter (it also shows where it's being forwarded to and what your mail filter program is, scary).
I've heard it's possible to make one of these files a named pipe connected to a script. I'm not exactly sure how it's done. (Other TAG members, please help.) You use "mkfifo" or "mknod -p" to create the special file, then somehow have a script running whose standard output is redirected to the file. Supposedly, whenever "finger" tries to read the file, it will read your script's output. But I don't know how your script would avoid a "broken pipe" error if it writes when there's nobody to read it, how it would know when there's a reader, or how the reader would pass identifying information to the script. Each Internet connection reveal's the requestor's IP, and if the remote machine is running the "identd" daemon, one can find out the username. But how your "finger" script would access that information, I don't know, since it's not running as a subprocess of "finger", so there's no way for "finger" to pass it the information in environment variables or command-line arguments.
However, "finger" is much less useful nowadays than it was ten years ago. Part of this is due to security paranoia and part to the fact that we use servers differently nowadays.
(1) Re security, many sysadmins have rightly concluded that "finger" is a big security risk and have disabled "fingerd" on their servers, or enable it only for intranet requests (which are supposedly more trustworthy). Not only is the host information useful to crackerz and script kiddiez, but users may not realize how much information they're revealing.
Part of this lay in the fact that finger daemons ran as the superuser, or root. On systems that have shadow passwords enabled, only root can read the file that has the encrypted password data. A malicious user wishing to obtain the superuser's password data could simply create a symbolic link from ~/.plan to /etc/shadow, and finger his or her own account (stolen or otherwise) to display the information!
This is due to the fact that fingerd was written in an era when most computers on the Internet were run by research institutions. The security was lax, and people didn't write software with resilience to mischief in mind. In fact, adding features was the main push behind most software development, and programs like fingerd contain some extremely dangerous features as a result.
There are, however, some modern implementations that take security into consideration. I personally use cfingerd, and have it configured with most of the options off. Furthermore, I restrict it to local traffic only, as was suggested earlier. I also know that my file security is maintained, since cfingerd will not follow symbollic links from .plan or .project files, and it runs as "nobody" (the minimal-privilege account that owns no files).
(3) "finger" only monitors login sessions. This includes the "login" program, "telnet", "xterm", "ssh" (and its insecure cousins "rsh" and "rlogin"). It does not include web browsing, POP mail reading, irc or interactive chat, or instant messaging. These servers could write login entries, but they don't. Most users coming from the web-browser-IS-my-shell background never log in, wouldn't know what to do at the shell prompt if they did log in, don't think they're missing anything, and their ISPs probably don't even have shell access anyway. That was the last nail in the coffin for "finger".
So in short, "finger" still works, but its usefulness is debatable. Linus used to use his ".plan" file to inform people of the current version of Linux and where to download it. SSC used to use it to propagte its public PGP key. There are a thousand other kinds of useful information it could be used for. However, now that everybody and his dog has a home page, this ".plan" information can just as easily be put on the home page, and it's just as easy (or easier for some people) to access it via the web than via "finger".
Kernel CompilationFrom Anthony Amaro Jr
Answered By Heather Stern
I have 2 computers currently, one running redhat 6.2 with 2.4.5 kernel (compiled from source) and another running redhat 7.1 stock. Why is it that after I do an almost identical install on both machines package wise, I am able to sucessfully compile and install the 2.4.5 kernel (from kernel.org) on the 6.2 machine but when I try to compile on the redhat 7.1 machine it the compiler stops with errors? It seems hard to believe that a newer version of red hat would be incompatable with the kernel that make it linux!!!
Thanks!
Anthony Amaro Jr.
answer 1: you can compile a kernel on a different system, then copy it, the matching System.map and modules across to your misbehaving one.
However, I don't know if this 7.0 problem remains in 7.1. (I'd bet they got a lot of complaints about it.) Soooo... with you having said nothing about what kind of error messages... how would we know either?
answer 2: "it's broken" is not enough detail for us to help "make it work".
Good luck, tho...
Re: Linux solution to syncing with Exchange Address books as a clientFrom Alan Maddison (published in 2c Tips, Issue 68)
Answered By Anthony E. Greene
I hope that you can help me find a solution before I'm forced back to NT. I have to find a Linux solution that will allow me to connect to an Exchange server over the WAN and then sync address books.
If you want to export the GAL for use in an LDAP server, you will need both Outlook and Outlook Express installed.
- Open Outlook.
- Open the Address Book and select the Global Address List
- In the Global Address List, select all the addresses you want to export and copy them to your Personal Address Book. This is a memory and CPU intensive process. I would advise selecting 100-200 or so at a time. Do not select distribution lists; they are not exportable.
- After all the desired addresses have been copied to your Personal Address Book, leave Outlook open and open Outlook Express.
- Select File->Import to import addresses from your Outlook Personal Address Book.
- After the import is complete, close Outlook.
- Select File-> Export to export your address book to a comma separated values (CSV) formatted text file. I will assumed you exported the following fields: Name, First Name, Last Name, Title, Organization, Department, Email Address, Phone, and Fax.
- After the export is complete, copy the CSV file to a box with Perl installed and run the following script (csv2ldif.pl):
See attached csv2ldif.pl.txt
Take the resulting LDIF file and import it into your LDAP server using its import tools.
Tony
internet cafeFrom gianni palermo
Answered By Heather Stern, Huibert Alblas
Dear sir,
please send me through email on how to setup an internet cafe in
detail using red hat linux and windows nt cause I am planning to setup
one. I got some tips from my friends but I want to consult a professional
like you. hoping yuo'll send me the details. thank you sir...
Gianni Palermo
...but nobody gave us any hints beyond what I had there. Maybe you can get away with very minimal services, like running all the stations from CD-based Linux distros. There are a bunch of them listed at LWN but some of them or more of a giant rescue disc than a usable system. You might try these:
- Knoppix
- http://www.knopper.net/knoppix
- RunOnCD
- http://my.netian.com/~cgchoi
- DemoLinux
- http://www.demolinux.org
- Virtual Linux
- http://sourceforge.net/projects/virtual-linux
...or only offering web access:
- Public Web Browser mini-HOWTO
- http://www.chuvakin.org/kiodoc/Public-Web-Browser.html
If you want to get more serious you'll need to look harder. Sadly Coffeenet was forced out of business by his landlord, so you can't get his codebase easily (besides, it would be a moderately ancient Linux by now). Since VA Linux is now going into the consultancy and software biz instead of hardware, maybe you can buy some of their E-mail Garden expertise.
Of course you wanted to know where to get started. So I'll give you a bunch of pointers, but for the rest you'll have to do your own homework. If you really want to you could start up an "Internet Coffee House HOWTO" and add it to the LDP. I'd sure enjoy pointing to it if it existed.
There are other important points beyond merely the technical setup to consider but I'll have to assume you're making business plans and selecting a good location on your own.
Here's what seem to be the most helpful HOWTOs right now for the topic. Most of them are also available at the Linux Documentation Project home page.
For being diskless, if you want to go that route:
- Diskless HOWTO
- http://www.linuxdoc.org/HOWTO/Diskless-HOWTO.html
- Thinclient HOWTO
- http://www.linuxdoc.org/HOWTO/Thinclient-HOWTO.html
- Network Boot HOWTO
- http://www.linuxdoc.org/HOWTO/Network-boot-HOWTO/index.html
- KIosk HOWTO
- http://www.linuxdoc.org/HOWTO/Kiosk-HOWTO.html
Getting the connection going:
- ISP Setup RedHat HOWTO
- http://www.chuvakin.org/ispdoc/ISP-Setup-RedHat.html
- Domain mini-HOWTO
- http://caliban.physics.utoronto.ca/neufeld/Domain.HOWTO
- DSL HOWTO
- http://www.linuxdoc.org/HOWTO/DSL-HOWTO/index.html
- DSL HOWTO "prerelease version"
- http://feenix.burgiss.net/ldp/adsl
- DHCP mini-HOWTO
- http://www.oswg.org/oswg-nightly/oswg/en_US.ISO_8859-1/articles/DHCP/DHCP.html
Protecting yourself from abuse:
- The Bandwidth Limiting HOWTO
- http://www.linuxdoc.org/HOWTO/Bandwidth-Limiting-HOWTO/index.html
- Security HOWTO
- http://www.linuxsecurity.com/Security-HOWTO
- Advocacy HOWTO
- http://www.datasync.com/~rogerspl/Advocacy-HOWTO.html
Maybe some things that might make your stations more attractive:
- Sound HOWTO
- http://www.linuxdoc.org/HOWTO/Sound-HOWTO/index.html
- XFree86 Touchscreen HOWTO
- http://www.linuxdoc.org/HOWTO/XFree86-Touch-Screen-HOWTO.html
- Printing HOWTO
- http://www.linuxprinting.org/howto
Last, but certainly not least:
Coffee HOWTO
It's a lot to read, but I hope that helps!
Its description:
One of the things I want to do here at the DNA Lounge is have public kiosks that people can use for web browsing, IRC, AIM, and so on. When most people set up kiosks, they tend to try and lock them down so that you can only run a web browser, but that's a little too limiting, since I want people to be able to run other applications too (telnet, ssh, irc, and so on.) So really, I wanted to give access to a complete desktop system. But do so safely and reliably.
I decided to set them up as Linux systems running the GNOME desktop, preconfigured with all the common applications people might want to run. However, I needed to figure out a way to make the system robust enough that one user couldn't screw it up for another, on purpose or accidentally. The system would need to be locked down enough that it was easy to reset it to a working state.
So, I had the following goals:
- When the machine boots up, it should automatically log itself in as "guest", and go to the desktop without requiring a login dialog.
- It should be possible to pull the plug on the machine at any time without loss of data: at no time should fsck need to run.
- Logging out or rebooting should reset the machine to a default state, clearing out any changes a previous user might have made.
- Small form factor: I wanted flat screens, and I wanted them without spending a fortune.
Its not using WinNT, but looks like you don't need to...
Have fun:
Halb
Password agingFrom Trevor Lauder
Answered Mike Ellis, Ben Okopnik, Heather Stern
How do I disable password aging without the shadow suite?
So - have you got shadow passwords? The easiest way to tell is to look at the password and shadow files. these are both colon-delimited data files. If you don't have shadow passwords enabled, the file /etc/passwd will look like this:
root:HTf2f4YWjnASU:0:0:root:/root:/bin/bash
The first field gives you the user name - I've only quoted the root user here, your password file will have many more users in it, but each line should follow the pattern shown above. The second field contains the users password, encrypted ...
There. That's better. When the choice is
a) give extra info that may be unnecessary or
b) shroud everything in mystery as a true High Priest should, I go with the Open Source version...
If you have shadow passwords enabled, the /etc/passwd file will look more like this:
root:x:0:0:root:/root:/bin/bash
Notice that the second field, which used to contain the password crypt, now has the single letter 'x'. The password crypt is now stored in the /etc/shadow file, which might look like this:
root:$1$17yvt96W$HO11W48wZuy0w9cPtQJdt0:11284:0:99999:7:::
Again, the first field gives the user name, and the second is the password crypt. These two examples use different crypt algorithms, hence the different length of the password field - this is not relevant to this discussion.
The remaining fields in the shadow file enable the password aging - according to "man 5 shadow", these fields are (in order)
Days since Jan 1, 1970 that password was last changed
Days before password may be changed
Days after which password must be changed
Days before password is to expire that user is warned
Days after password expires that account is disabled
Days since Jan 1, 1970 that account is disabled
A reserved field
The manual page also reads:
"The date of the last password change is given as the number of days since Jan 1, 1970. The password may not be changed again until the proper number of days have passed, and must be changed after the maximum number of days. If the minimum number of days required is greater than the maximum number of day allowed, this password may not be changed by the user."
So, to disable password aging (as in the example) set the fourth field to zero and the fifth to a large number (e.g. 99999). This says that the password can be changed after no time at all, and must be changed after 274 years, effectively disabling the aging.
ben:ShHh!ItSaSeCrEt!:11504:0:::::
If you do that, "chage -l" reports the following:
ben@Baldur:~$ chage -l ben Minimum: 0 Maximum: -1 Warning: -1 Inactive: -1 Last Change: Jul 01, 2001 Password Expires: Never Password Inactive: Never Account Expires: Never
On the other hand, if you edit the file directly you MUST get the number of colons right. Otherwise nobody whose login is described after the line you get wrong, will be able to get in... unless by chance you have more than one wrong, and your other mistakes make them line up properly again, in which case there will be a block of people who cannot login. This can be very hard to debug if you don't know to look for it...
Hope it helps!
inetd and figletFrom Nick Moffitt
Answered By Ben Okopnik, Heather Stern, Don Marti
![]() I run a server machine, and I have telnet disabled in favor of
OpenSSH. What I have done is add the following line to my
/etc/inetd.conf:
I run a server machine, and I have telnet disabled in favor of
OpenSSH. What I have done is add the following line to my
/etc/inetd.conf:
telnet stream tcp nowait nobody.nogroup /usr/sbin/tcpd /usr/bin/figlet Unauthorized access prohibited. Go away.
The idea is to print out a "NO TRESSPASSING" sign in big block letters using the figlet utility. It works great, and when I run "telnet localhost" from this machine, I see:
----8<----
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
_ _ _ _ _ _
| | | |_ __ __ _ _ _| |_| |__ ___ _ __(_)_______ __| |
| | | | '_ \ / _` | | | | __| '_ \ / _ \| '__| |_ / _ \/ _` |
| |_| | | | | (_| | |_| | |_| | | | (_) | | | |/ / __/ (_| |
\___/|_| |_|\__,_|\__,_|\__|_| |_|\___/|_| |_/___\___|\__,_|
_ _ _ _ _ _
__ _ ___ ___ ___ ___ ___ _ __ _ __ ___ | |__ (_) |__ (_) |_ ___ __| |
/ _` |/ __/ __/ _ \/ __/ __| | '_ \| '__/ _ \| '_ \| | '_ \| | __/ _ \/ _` |
| (_| | (_| (_| __/\__ \__ \ | |_) | | | (_) | | | | | |_) | | || __/ (_| |_
\__,_|\___\___\___||___/___/ | .__/|_| \___/|_| |_|_|_.__/|_|\__\___|\__,_(_)
|_|
____
/ ___| ___ __ ___ ____ _ _ _
| | _ / _ \ / _` \ \ /\ / / _` | | | |
| |_| | (_) | | (_| |\ V V / (_| | |_| |_
\____|\___/ \__,_| \_/\_/ \__,_|\__, (_)
|___/
Connection closed by foreign host.
----8<----
This is all well and good, but when I try telnetting from a remote machine, it's a crap shoot. Sometimes I'll get the whole banner, and sometimes I'll get nothing. One machine reliably prints out the correct text up until it ends as follows:
----8<----
____ / ___| ___ __ ___ ____ _ _ _ | | _ / _ \ / _` \ \ /\ / / _` | | | | | |_| | (_) | | (_| |\ V V / (_| Connection closed by foreign host.
----8<----
What could be causing this, and how should I fix it?
If you are going to hack source anyway, hack source of something that's closer to doing the right job, I'd think.
#!/bin/sh figlet 'Go away!'
It should work fine. Should be fairly secure, too.
#! /bin/sh /usr/bin/figlet $* && sleep 1
![]() Aha, yeah. That seems to do the trick.
Aha, yeah. That seems to do the trick.
![]() Yeah, I got the same thing when I tried that. I had
considered doing something to tcpd that would make it handle leftover
buffers more correctly, but putting in the sleep seems to work well
enough for me.
Yeah, I got the same thing when I tried that. I had
considered doing something to tcpd that would make it handle leftover
buffers more correctly, but putting in the sleep seems to work well
enough for me.
Thanks!
 More 2¢ Tips!
More 2¢ Tips!
 Globally Adding X Startup Commands on a Debian System
Globally Adding X Startup Commands on a Debian SystemSometimes you'd like to configure an application so that it starts for any user who uses 'startx' (or logs in through xdm?). For example, I have a policy on my systems that all users should be running xautolock (a program that invoke an xscreensaver or xlock module after a period of mouse/keyboard inactivity).
On a Debian Woody/Sid (2.2 or later) system this can be done by copying or linking a file into /etc/X11/Xsession.d/. This would be a script similar to one you'd add to /etc/init.d/. For example I added a file called 60xautolock consisting of the single line:
/usr/bin/X11/xautolock -time 2 -corners 00-+ -cornerdelay 2 &
I suspect it should be marked as executable; I just set the perms on mine to match the others therein.
(BTW: this xautolock enables a "blank now" hot spot in the lower right corner of the screen, and a "never blank" hot spot in the lower right; so a user can blank the screen with a 2 second delay by shoving their mouse pointer far into the corner; it also sets the automatic blanking to occur in 2 minutes: the default of 10 min. is way too long!)
.Xauthority files for Debian startxHere's another Debian tip:
Debian normally configures xdm to invoke the X server with the -auth argument. This allows one to configure their X session to allow remote clients, or local clients under other user IDs to connect to the X server (to run in your X session).
This is useful even if you've accepted the recommendation to configure Xfree86 4.x with the "-nolisten tcp" option (to disable remote clients from direct X protocol access). It allows you to run X under you're own user ID while allowing root to open programs on your display (particularly handy if you want to run ethereal, which will refuse to run SUID/root but which needs access to X and root permission to sniff on your network interfaces).
The problem is that Debian doesn't normally invoke X with the -auth option when you use the startx script. Of course you could use xhost +localhost; but this allows any local user to access your X session; rather than allowing you to control it in a more fine-grained fashion.
The solution is to edit the /etc/X11/xinit/xserverrc file, inserting one command and adding an option to another:
#!/bin/sh /usr/bin/X11/xauth add :0 . $(dd if=/dev/urandom count=2 2> /dev/null | md5sum) exec /usr/bin/X11/X -dpi 100 -nolisten tcp -auth $HOME/.Xauthority ## . . . . . . . . . . . . . . . . . . . . ^^^^^^^^^^^^^^^^^^^^^^^
... last comment line (starting with ##) underscores the addition to that command. The xauth command is being used to create the ~/.Xauthority file.
For root to gain access to this session you'd issue a command like:
xauth -f ~$YOU/.Xauthority extract - `hostname`/unix:0 | xauth merge -
... from a root shell (perhaps by opening an xterm and using the su or sudo commands). (Hint: obviously anyone who can read your .Xauthority file can use it to gain access to your X sessions; so maintaining these on NFS home directories is BAD; yet another reason why NFS stands for "no freakin' security").
for remote X client access: USE SSH with X11 forwarding!That's the easiest and most secure means available for supporting remote X clients; if you call the OpenSSH client with the -X (enable/request X11 forwarding) and if the remote ssh daemon allows it; and if you have your DISPLAY variable set (which is always the case when you start an xterm under X; since it's how the X libraries linked into xterm "found" your X server) then the remote daemon will spawn off a proxy --- an instance of the daemon that will "pretend" to be an X server on display number 10, 11, or higher. That daemon will automatically relay Xprotocol events to your client which will relay them through the local Unix domain socket to your server. This is all automatic with most versions of ssh (except for the newer OpenSSH client which defaults to disabling X11 forwarding and thus requires the -X switch).
Please make sure you use capital X, as -x in lowercase tells it to disable this feature, even if the local sysadmin has chosen to okay a tunneled X connection by default. -- Heather
This allows you to run X with ports 6000 (and up) closed; (preventing remote systems from even seeing that you're running it; much less giving them the opportunity to attack your X server) and still allows you to easily support remote X clients.
SSH X11 forwarding also works through NAT/IP masquerading and any firewall that allows other ssh traffic.
2C Tip Root PasswordThis matter has come up many times before, and will surely come up many times in the future. I hope by putting Yan-Fa's crisp description and our extra notes in Tips, that more people who need it, will find it easily. -- Heather
There's a simpler way to put a new root password on a linux system if you've forgotten it and have physical access. Which I haveto assume this person has since they're messing with partitions.
If you have lilo installed, interrupt the boot up process
at the lilo prompt and type:
kernelImageName single
(one example would be linux as your kernelImageName.)
-- Heather
This will boot you up in single user mode and allow you to chance the password. This has the added advantage of running all the standard run level 1 processes, including mounting of partitions.
Yan-Fa Li
Things to look out for, however:
2C Answers: RH7.1 switch to KDE login as defaultIf you like to get your hands dirty you can also edit the /etc/sysconfig/desktop file (or create it if it doesn't exist) and put in the line: DESKTOP=KDE
This has the added advantage of changed the XDM to KDM instead of GDM.
Y
2 cent tip: a quick email address finderHi,
From the Department of Scripting Newbieville, here's a tiny function I've added to my .bashrc and ended up using quite often:
addy ()
{
if [ $# -eq 1 ]
then
grep -i "$1" "$HOME/.mail_aliases" | mawk '{ print($3) }'
else
echo "Usage: addy <searchstring>"
fi
}
Given a search string (part of a name, nickname or address) as input, it'll output any matching email addresses it finds in an email aliases file (~/.mail_aliases, in this case). The alias file contains lines in the format used by mutt - for example:
alias nickname whoever@wherever (Real Name)
If you use WindowMaker and have xmessage, you can add something similar to a menu by adding the following, as a single line, to the menu config file of your choice:
"Find email address..." SHEXEC "xmessage -nearmouse
`grep -i \'%a(Email address finder,Enter search string:)\'
.mail_aliases | mawk '{ print($3) }'`"
Thanks to everyone involved with Linux Gazette - you're great!
Tim
djbdns? Feh! Get a free-software name server insteadHmm, Answer Gang recommended djbdns without mentioning that it's proprietary software? Ouch. Bad gang, no biscuit.
I said "some" and I didn't mention how many people are currently signed onto TAG. It's more than two. Maybe next time I'll gather the whole flaming thread from across its 3 mailing lists.
However I've cc'd the Gang at large so a few more people can take
a bushwhack at me
![]()
I ragged on his philosophy a tiny bit and noted that I won't use it. Even, a technical rather than religious/copyright reason not to.
But I was also slaving over hot perl scripts and HTML mashed taters
trying to get the mailbag and tips sections cooked. If you smell smoke
coming out of my ears that's surely my melted brain
![]()
-- Heather
Thanks Rick! Everyone else, I hope you find this particular 2c tip especially handy. I'd enjoy hearing some folks will tell us how useful or annoying they find these things.
Your article about rbl going commercial?I see no signs that they want any money from me. Can you point me to a URL that wants payment?
Sure.
Here's the subscription policy page, clarifying that their stuff is subscription-only now, and why:
http://www.mail-abuse.org/subscription.html
Here's the Fee Structure page that it points to:
http://www.mail-abuse.org/feestructure.html
(note, you really want tables support to read that)
... so it merely depends on who you are.
Printer setup on Slackware 8?????Which tool must I now use to set up a printer? it used to be printtool on older systems (RedHat/Mandrake)
Please !
Danie Robberts
The Answer Gang replied with a few distro specific notes:
Seg FaultNot really sure how to get this where it needs to go.
This is the right place. It will be published in next month's 2-Cent Tips, unless Heather has too much other material. -- Mike
I have recently had the same problem with random seg faults that you addressed in August TAG.
I bought a new computer, pieced it together, and put 384M in it. When I initially installed linux, it was dog slow, and running top, I noticed that I only had 64M visible (I think, incredibly less that 384 to be sure). I did a little checking and learned that the motherboard has a known problem of not seeing all the memory. So I entered the line "mem=384M". I then started getting random seg faults. I couldn't figure it out for a long time.
Even though I had a graphics card with on-board memory, my bios still alotted 64M to the AGP device on the motherboard. I reduced this (couldn't get rid of it, or set to 0), and allowed for the use in my lilo.conf entry, and all is wonderful now.
Sorry about the verbosity.
-Tom
SMTP Auth with Debian potato and eximHi,
I have done some reading and searching but the solution to our problem still eludes me.
I volunteer for a non-profit freenet ccil.org and would like to setup smtp
authenication so that CCIL users who buy connectivity from other ISP's
will continue to use our stable and reliable mail sevices. The system our
mail runs on is a Debian potato box running the default smtp server exim.
Can you point me to a HOWTO?
Thanks,
Chuck
Are you asking how to allow users of your systems to access mail on your system even though they are not in your domain? If so, you want a program called pop-before-smtp (here's one URL I found over on google: http://rpmfind.net/linux/RPM/PLDtest/i686/pop-before-smtp-1.21-3.noarch.html ).
It's easy to setup and allows your users to access their email from anywhere in the world.
-- Sincerely, Faber Fedor
Source controlHas anybody tried Subversion? According to the web page (http://subversion.tigris.org), it's at Milestone 2 alpha development, and aims to have all CVS features plus:
It was recommended by someone on the Cheetah (http://www.cheetahtemplate.org) mailing list.
At print time, it reached its Milestone 3, is now self hosted (they use their own code and not CVS anymore), and they hope to be feature complete in early October.
Compare also Bitkeeper, (www.bitmover.com), a project by Larry McVoy and others aimed toward successful source control of big, complicated projects. -- Heather
Kernels?? on a SparcHi,
Can you use the same source for compiling a kernel on both an Intel based machine as well as a Sun?
I would like to know before I break my Sun
thanx
Danie
It should automatically detect the architecture it's compiling on and produce the right kernel.
However, whenever you install a new kernel, you always want to have a plan of escape in case the new kernel doesn't boot. That means making sure your old kernel is still ready to go and you know how to switch back to it. Popular ways to do this are to put the new kernel on a boot floppy, leaving the hard-disk setup alone, or arranging for LILO to boot one or the other from its menu. I'm not sure if Sun computers have LILO (Alphas use a multi-OS program called MILO instead), but they should have something equivalent. -- Mike
I can answer that. They use SILO, which works a little differently from LILO, but in a way, it makes it much easier to have multiple kernels.
Booting a Sparc takes more code than a PC does, but the disk partitioning utilities available to linux are not real clear on that concept. So SILO installs a tiny first stage loader whose only job in the whole world is to find the second stage. The second stage has more room than LILO does, so it is also smart enough to read its own config file. Thus SILO doesn't need to be re-invoked all the time when you make configuration changes.
But I wouldn't change what you let the bootprom memorize, until you are dead certain the new one works.
I'll add that the Sparc Debian disc might make an acceptable rescue disc if you get really screwed up, but it's still better to be careful. -- Heather
portal for a newbie?What combination of open source software should be used to create a portal site? How could a beginner build and test such a site?
The Gang replies:
Thank you for the reply. It is very helpful. Gives me a lot of new places to look.
peace
![[picture of mechanic]](../gx/adam/mechanic.png)
Hello there, dear readers. How have you all been? Not too busy I trust. I on the other hand have been busy over the last month or so. I have just completed my A-level exams, which I found to be quite tiring. That was why I was unable to write the Weekend Mechanic last month. For those of you who are currently doing, or are thinking of taking A-levels, I would advise you that although they are good fun they require lots of hard work.
As a result of completing my A-levels (these are university entry exams) I have also left school. Although for me this is rather sad, it does mean that I shall have lots of time to develop my Linux ideas. Thus, over the holidays I am hopefully going to be teaching an evening class about using Linux. It is something that I am looking forward to.
But I don't wish to delve too much into the future. Going back to the world of computing one thing that happened recently which I found quite amusing was that a young computer cracker (age 19 years, whose name I cannot remember) from Wales (UK), had gotten a load of credit-card details and posted them onto another website. Amongst the credit-card details obtained was that of Bill Gates. This young cracker then used his credit-card, ordered a consignment of viagra, and sent it to Bill Gates!!!
You'd have thought that the Welshman would have had something better to do.........
The internet is growing at an alarming rate. Indeed, with nearly every ISP there is the opportunity of being able to publish your own web pages. The ability to do this is through the use of a computer (the host), and a webserver program such as Apache. Although there are other webservers, Apache is the most widely used on the internet and is the most stable.
"But why would you want to use it on a local machine?", I hear you cry. Well running the Apache httpd daemon on your Linux box means that it is a great way of storing information, especially if you have a lot of HTML pages. I happen to have Apache running because I have a local copy of all the LDP Howto's, and of course a copy of the Linux Gazette archives!!
So the first thing to do is to test whether or not you have Apache installed. If you are using a distribution that uses the RPM file format, type in the following:
rpm -qa | grep -i apache
If successful you should see a line similar to:
apache-1.3.12-95
This means that the Apache webserver has been installed. If you do not have Apache on your system then you must install it. Many distributions come with Apache so the chances are it is on your distribuion CD. If it is not, or your distribution does not support the rpm format, then you must download the source files in tarred/gzipped format (*.tar.gz) available from www.apache.org. Once you have downloaded the files you can usually install apache in the following way:
1. Log in as Root
2. Gunzip/untar the file:
tar xzvf /path/to/tarfile/apache*.tar.gz
3. cd to the newly created Apache directory:
cd Apache*
4. Run the "configure" script:
./configure
5. That will take a minute. Hopefully, that should be successful, and a makefile, called "Makefile" should exist in the directory. If not, it is likely that you do not have any compiler programs (such as C, C++, g++), or you header files, or kernel source files installed. It might also be possible that your make utility is not installed. If this is true then you must install them.
So once configure has finished the thing you have to do now is to "make" the file, by typing in the following:
make
This step may take some time, especially if you have an old machine.
Assuming there were no errors from the make, the last thing you have to do is to install the compiled files by typing:
make install
And hopefully that should have installed Apache. If you do encounter errors while installing/compiling Apache read the documentation that comes with it. One caveat that I will mention is that during the "make" process it is normal for the information to be echoed to the screen. If you find that you are getting repeated errors while compiling Apache, one work around is to issue the following command:
make -k all
The above command will force make to continue, even if it encounters errors en route. Although I only recommend using it as an absolute last resort. Invariably reading Apache's documentation should solve most compiler issues.
Now that everything has been installed the next thing to do is to start Apache. This is accomplished by starting the "httpd" daemon. By default (or at least for me anyway) Apache is automatically run during your run-level so if you have not already rebooted your machine type what follows still as user "root":
httpd
Hopefully your prompt should have been returned with nothing echoed to the screen. To check that the "httpd" daemon is running, we can use our old friend "ps", thus:
ps aux | grep -i httpd
What the above command does, is to list all the processes (including those that are not attached to a tty), and then filters the list (pipes "|") it to the grep command, which will match for the expression "apache". The switch -i ignores case sensitivity.
You should see a number of lines, but one which looks similar to the following:
wwwrun 1377 0.0 2.0 4132 1340 ? S 11:09 0:00 httpd
This means that Apache is up and running. If you find that the result of that command simply returns "root blah blah grep -i httpd" then you must run httpd again. If you keep getting the same message, switch to init 6
OK, now were are getting somewhere. Having ensured that the "httpd" daemon is active, we can actually start playing with it. Open up a copy of a Web browser (such as Netscape) and enter the following URL:
http://localhost
Hopefully you should see a web page of sorts. This usually differs between different Linux distributions. On my SuSE box I am presented with the SuSE Support Database with the SuSE chameleon mascot in the top middle of the page!
The page that you are looking at is the main page at the site "localhost". This page is stored in the following directory:
/usr/local/httpd/htdocs
This directory has a special name. It is called DocumentRoot.The actual path may vary slightly on some systems, but invariably it is similar to the above. In this directory you should notice some files, in particular *.html files. The file that is loaded when you go to "http://localhost/" is the file index.html. What I have done, is created a sub-directory in "htdocs" called "oldhtdocs", and copied all the files into it. That way, I can start afresh, and know that I have the originals if I need them.
You may find, that reading and writing to the DocumentRoot folder has been disallowed to non-root users. To get around this issue the following command as root, replacing "/path/to/htdocs" with the correct pathway:
chmod +rw /path/to/htdocs
Knowing now, where the files are located for "http://localhost/" is all very well, but how do you configure apache? Hang on there reader......the file you are looking for is called httpd.conf and is located usually in "/etc/httpd" or it maybe in the directory "/usr/local/apache". On SuSE and Mandrake systems, the latter is the default place. In the sections that follow I shall be using the "httpd.conf" file to carry out various customisations.
How many of you have gone to URL's that contain the tilde symbol (~) followed by a name and then a (/)? I would imagine that nearly everyone has, at sometime. But how many of you were aware of what it meant?? The tilde symbol within a URL indicates a "subdomain" that is owned by a user on the computer system, off the main domain name. Thus, at school, I had my own webserver, with a valid URL:
http://linuxservertom.purbeck.dorset.local/~thomas_adam/
What this was doing, was actually retrieving files stored in a special folder under the user account, of user "thomas_adam". This ability, gives users on a network, a space on which to house their own web pages. So how is all this achieved? Well, it is quite simple really....
All users, who are allowed their own webspace, have to be put in the group nogroup (or www-data under Debian, etc). This can be done, by editing the file "/etc/group" (as root), and locating the line for "nogroup". Then at the end of the line, add the users' name separated by a comma. Then save the file.
In a user's home directory, a directory called public_html has to be created, thus (as user root type):
cd /home/auser/ && mkdir public_html
Where "auser" is the name of a valid user on the system. Then the permissions have to be set. This is done by typing in the following:
chmod 755 /home/auser/public_html
Then the last thing to do, is to set the group of that newly created folder to nogroup. This can be done, by typing:
chown auser.nogroup /home/auser/public_html
Where "auser" is the name of the valid user.....substitute as appropriate. The same procedure can be applied to all users. It might also be an idea to play about with "useradd" so that when you add new users, the "public_html" directory with the permissions are set automatically.
[Actually, you don't have to do all that user and group
stuff, if you instead make sure the public_html directory and
all its files are world readable:
chmod -R a+r /home/auser/public_html
The important thing is that Apache has read access to the files. -- Mike Orr]
So the next thing to do, is to make sure that Apache is aware of what we have done. Open up the "httpd.conf" file, and lets take a look......
By default, I think that the configuration that tells the Apache about the public_html directive is commented out, or at least it was in mine. From the beginning of the document, search for the keyword UserDir. You should find something that looks like the following:
<IfModule mod_userdir.c>
UserDir public_html
</IfModule>
If any of the above lines have a hash (#) symbol preceeding them, delete them. The above lines tell Apache that the directory "public_html" is to be used for html files for each user.
Directly below this are more related lines that tell apache what sort of restrictions to apply. In the case of the following lines they are read-only. If any of these are commented out, uncomment them.
<Directory /home/*/public_html>
AllowOverride FileInfo AuthConfig Limit
Options MultiViews Indexes SymLinksIfOwnerMatch IncludesNoExec
<Limit GET POST OPTIONS PROPFIND>
Order allow,deny
Allow from all
</Limit>
<LimitExcept GET POST OPTIONS PROPFIND>
Order deny,allow
Deny from all
</LimitExcept>
</Directory>
So now all that remains is to start to write the web pages. The only other thing which you will find extremely useful is that if you noticed my example earlier:
http://linuxservertom.purbeck.dorset.local/thomas_adam/
I had not specified a ".html" file to load. This is because I had already told Apache a default file to look for within it. Such a file is known as a DirectoryIndex, and you can specify default files to load. Locate the following in your "httpd.conf" file:
<IfModule mod_dir.c>
DirectoryIndex index.html index.shtml lwm.html home.html
</IfModule>
What this is telling Apache is that when a URL is specified, such as the example above, with no extension file after it (*.htm*), then it will look for a default file(s) specified after the flag "DirectoryIndex". Thus in your "public_html" file, if there was a file called "index.html", then this would be loaded on default. You are able to specify multiple files as in my example above. If Apache cannot find anyone of the above files then the directory listing is displayed instead (unless you specify a file to load).
One thing that I would like to mention at this point, is if you have specified a hostname in "/etc/hosts", you can substitute that name in place of "http://localhost". It is for convienience that I use it here. Furthermore in "httpd.conf", I would recommend that you find the following flag and substitute localhost for the first part of your host name:
ServerName grangedairy
Thus my host name is grangedairy.laptop, I have simply put grangedairy. The reasons for doing this will become apparant from reading the Alias Section
The last thing you have to do is with any changes that you make to "httpd.conf", you have to stop and restart it. This can be achieved by typing in the following (as root):
killall httpd httpd
In this section, I shall be covering the rather short topic of Aliases. Using the "httpd.conf" file, we can see a list of aliases if we search for the keyword "alias". Hopefully you should see a list which looks similar to the following:
Alias /howto /usr/share/doc/howto/en/html/ Alias /mini /usr/share/doc/howto/en/html/mini/ Alias /lg /usr/share/doc/lg/ Alias /hilfe /usr/share/doc/susehilf/ Alias /doc /usr/share/doc/ Alias /cgi-bin-sdb /usr/local/httpd/cgi-bin/ Alias /sdb /usr/share/doc/sdb/ Alias /manual /usr/share/doc/packages/apache/manual/ Alias /htdig /opt/www/htdocs/htdig/ Alias /opt/kde/share/doc/HTML /opt/kde/share/doc/HTML/ Alias /opt/gnome/share/gnome/help/ /opt/gnome/share/gnome/help/ Alias /errors/ /usr/local/httpd/errors/ Alias /icons/ /usr/local/httpd/icons/ Alias /admin /usr/local/httpd/admin/ Alias /lwm /usr/share/doc/lg/lwm/
As you can see, what the above is saying, is that if the URL ends in a "/howto" for example, then Apache is to get its web pages from the directory "/usr/share/doc/howto/en/html". Once again the default web page that it will load up is taken from DirectoryIndex, as we saw earlier.
http://grangedairy/howto
You may remember that earlier I had said that you should specify a ServerName flag in "httpd.conf". This was done so that when you typed in the URL with one of the above aliases, you do not need to put an extra forward slash at the end of the URL. You see, originally, the above aliases, were alised thus:
Alias /howto/ /usr/share/doc/howto/en/html/ Alias /mini/ /usr/share/doc/howto/en/html/mini/
with extra forward slashes after the alias name. I soon got tired of having to add this in myself and so I was able to tell Apache how to do this for me. By setting the ServerName flag apache now knows the name of my machine so that when I go to:
http://grangedairy/howto
It automatically appends the forward slash at the end. Cool, eh?? So if you have done the same as me you can delete the trailing forward slashes from the alias name because hopefully, you should not need them!
The final part to my Apache tutorial is how to set up and create "secure directories", i.e. those that require user authentication before they are loaded. You will have noticed earlier that in my listing examples of Aliases, there was one for "/admin". This is in fact a secure directory.
You can set up secure directories in the same way that you would an ordinary alias except this time, you have to tell Apache a little bit about the directory itself and how it is to be parsed. So say that you wanted to set up a secure directory mysecuredir, at location "/usr/local/httpd/mysecuredir/" You would do the following:
1. Add "/mysecuredir" to alias list:
alias /mysecuredir /usr/local/httpd/mysecuredir
2. Change to the location of the folder that you have specified in the alias list, thus:
cd /usr/local/httpd
3. Create the directory "mysecuredir" by typing in:
mkdir mysecuredir && cd mysecuredir
This has created the directory, and changed to it.
4. Now the work begins. There are two files that we shall be using .htaccess and htpasswd. The first file (.htaccess) is the one that we shall set up first. It is this file that will store the information about how the "mysecuredir" is to be used.
So at the console, use an editor such as nano (a pico clone), jed, emacs, etc, to create the .htaccess file, and enter the following information, exactly as shown because apache is case-sensitive in parsing commands!:
AuthType Basic AuthName "Restricted Directory" AuthUserFile /usr/local/httpd/admin/htpasswd require valid-user
(Since ,htaccess starts with a period, it won't show up in ordinary directory listings. Use "ls -a" to see it.)
The commands above are the most common ones used to create a secure directory. The table below will give a short description of the commands and how you can customise them.
| Option Tag | Meaning |
|---|---|
| AuthType | This sets the authentication type. Basic is usally always used. |
| AuthName | Sets the name on the "login" box of the directory that you are trying to connect to (see the screenshot below). |
| AuthUserFile | This is the file that is used to check for authentication, i.e. it stores your username and password (encrypted of course). You must ensure that you use the full path to the htpasswd file. |
| require valid-user | This says that access is only allowed to those who have a valid entry in the htpasswd file. |
Note: for additional security, put the htpasswd file somewhere that is not accessible via URL--somewhere outside your web directory and outside your alias directories. A .htaccess file must be in the URL-accessible directory it's protecting, but the htpasswd file may be anywhere. You may also share the same htpasswd file among several .htaccess directories if desired.
Ok, now that we have told apache how to handle the directory we now need to create the password file:
5. To create the htpasswd file you have to type in the following command (in the same directory as the ".htaccess" file:
htpasswd -c htpasswd username
Whereby you replace "username" with your username. To keep adding users to the file, issue the same command, but remove the "-c" flag.
6. Now edit our friend /etc/httpd/httpd.conf and at the bottom of the alias list, add the following:
<Directory /usr/local/httpd/*>
AllowOverride AuthConfig
</Directory>
You may have to modify it slightly, but that will ensure that if apache meets any ".ht*" files it will use them to apply security on them. To turn off this, for the above, change AllowOverride AuthConfig to AllowOverride None.
Now stop and restart the httpd daemon
Ok now you are all set to try it out. Having saved the files go to your web browser and type in the following:
http://servername/mysecuredir
Making sure that you replace "servername" with either your hostname, or "localhost". If successful you should see a dialog box similar to this screenshot.
Once you have entered the correct details you should then be off and away. You may find however that you can connect to the "mysecure" directory without having to supply any credentials. If this happens, you need to check the following in your "/etc/httpd/httpd.conf" file.....
It may be that apache has not been configured to recognise the use of ".ht*" files. You can tell Apache to undo this, by setting the AccessFileName tag, thus:
AccessFileName .htaccessWell, that concludes this entire section. I did consider writing a few words about the use of perl and cgi, but I decided that Mark Nielsen has done a better job over the last few months. Furthermore, Ben Opoknik has been creating yet another excellent tutorial, this time on Perl, so if you are interested in cgi programming, I would start by reading these two series of articles :-)
I stumbled across this program quite by accident. I was originally doing some research at school for the acting network administrator (hi Dave!) which involved the use of power management, as we were having some problems with monitors "sleeping (room D25)" but I digress.....
UPX (Ultimate Packer for eXecutables) is a compression program. What this program actually does, is
compress binary executable files which are self contained, and which do not slow down execution or memory
performance. A typical use for this type of program is best suited to laptop users, where harddrive space is of
enormous concern. Since I use my laptop for most things and only have a 3.2GB harddrive, I have found that
compressing the files stored in "/usr/bin" has cut the size of that directory in half!
Since it will only compress binary files, it is no good trying to compress the files stored in "/etc" for example. I have found that compressing the following directories is ok:
/usr/bin /usr/X11R6/bin /usr/local/bin
One caveat that I should mention, is that I would NEVER use "upx" to compress the files stored in both "/bin" and "/usr/sbin" When I rebooted my computer, I found that Init would not run. Out came "Tom's root/boot" and I later discovered that the compression of these files was causing the main Init program problems for some reason........
So to use the program, download the package from http://wildsau.idv.uni-linz.ac.at/mfx/upx.html. I think you have the choice of either downloading the source packages, or a pre-compiled executable.
I simply downloaded the pre-compiled package, unpacked it, and copied the main upx program to "/usr/bin". then you are ready to start compressing files.
To compress a file, you have to type in the following:
upx /path/to/program/progname
and that will compress the program specified. You can also compress all files in the directory, by typing:
upx /path/to/programs/*
and UPX will happily go through all files, and instantly disregard those which are not Linux/386 format.
Here's a screenshot of UPX in action.
To decompress files, you have to use the "-d" flag, thus:
upx -d /path/to/prog/*
A common list of command-line options, are:
Usage: upx [-123456789dlthVL] [-qvfk] [-o file] file.. Commands: -1 compress faster -9 compress better --best compress best (can be very slow for big files) -d decompress -l list compressed file -t test compressed file -V display version number -h give this help -L display software license Options: -q be quiet -v be verbose -oFILE write output to `FILE' -f force compression of suspicious files --no-color, --mono, --color, --no-progress change look Backup options: -k, --backup keep backup files --no-backup no backup files [default] Overlay options: --overlay=copy copy any extra data attached to the file [default] --overlay=strip strip any extra data attached to the file [dangerous] --overlay=skip don't compress a file with an overlay
Overall, the performance of the compressed files have been ok, and I have not noticed any loss in functionality. The only program that did take a long time to load up once it had been compressed was netscape but that did not bother me too much (netscape uses so much memory, I am used to waiting for it to load).
In issue 67 of the Linux Gazette, Mike Orr, reviewed cowsay/cowthink, a configurable talking cow that displays messages in speech bubbles. Everything is written in Perl (my second-favourite scripting language, after bash) and is displayed in ASCII. I was so impressed with the cows that I decided to look for more ASCII programs. Out came my SuSE distribution CD's and I found the program bb.......
bb is a fully-working ASCII demo, which uses ANSI C and is SVGA compatible. bb makes use of the aa_lib package (ASCII art library) so you will have to install it along with the main package. The demo produces a range of different simulated pictures, from random tumbling characters (going through different shades of grey), to an ASCII simulated mandlebrot fractual!! (which incidentially inspired the colour version of Xaos).
You can get bb from ftp://ftp.bonn.linux.de/pub/misc/bb-1.2.tar.gz.
bb used to have a home page, but unfortunately it's gone. However, project aa (the ASCII Art library) is what bb is based on, and it has a home page at http://aa-project.sourceforge.net/. The aa page also discusses aview (an ASCII art viewer), aatv (to view TV programs on your text console), ttyquake (a text version of Quake), Dumb (a Doom clone), apron (an mpeg1 player), and other programs. ttyquake does require the graphical Quake to be installed, so it uses the original Quake game files. One commentator writes of ttyquake, "people are starving to death in this world... and somebody had time for this....."
bb is best run from the console, but it can be run from within an X-terminal window, as shown by this screenshot.
The valid command-line options for bb are:
Usage: bb [aaoptions] [number]
Options:
-loop play demo in infinite loop
AAlib options:
-driver select driver
available drivers:linux curses X11 stdout stderr
-kbddriver select keyboard driver
available drivers:curses X11 stdin
-mousedriver select mouse driver
available drivers:X11 gpm cursesdos
Size options:
-width set width
-height set height
-minwidth set minimal width
-minheight set minimal height
-maxwidth set maximal width
-maxheight set maximal height
-recwidth set recomended width
-recheight set recomended height
Attributes:
-dim enable usage of dim (half bright) attribute
-bold enable usage of bold (double bright) attribute
-reverse enable usage of reverse attribute
-normal enable usage of normal attribute
-boldfont enable usage of boldfont attrubute
-no<attr> disable (i.e -nobold)
Font rendering options:
-extended use all 256 characters
-eight use eight bit ascii
-font <font> select font(This option have effect just on hardwares
where aalib is unable to determine current font
available fonts:vga8 vga9 mda14 vga14 X8x13 X8x16
X8x13bold vgagl8 line
Rendering options:
-inverse enable inverse rendering
-noinverse disable inverse rendering
-bright <val> set bright (0-255)
-contrast <val> set contrast (0-255)
-gamma %lt;val> set gamma correction value(0-1)
Ditherng options:
-nodither disable dithering
-floyd_steinberg floyd steinberg dithering
-error_distribution error distribution dithering
-random <val> set random dithering value(0-inf)
Monitor parameters:
-dimmul <val> multiply factor for dim color (5.3)
-boldmul <val> multiply factor for dim color (2.7)
The default parameters are set to fit my monitor (15" goldstar)
With contrast set to maximum and bright set to make black black
This values depends at quality of your monitor (and setting of controls
Defaultd settings should be OK for most PC monitors. But ideal monitor
Needs dimmul=1.71 boldmul=1.43. For example monitor used by SGI is very
close to this values. Also old 14" vga monitors needs higher values.
I really do think that if you're into ASCII art, you should give this demo a go. It lasts for approximately 5 minutes.
Well, you've made it to the end of this months article. Looking ahead to next month, I am going to be writing an article about how to write efficient manual pages (anyone remember groff processing??) and whatever else I can think of. However it would be nice to hear from anyone who has article suggestions, as I am running out of ideas.....slowly. If there is anything you feel would be good to include in the LWM, drop me a note :-)
Also, in case anyone is interested, all the screenshots that have appeared in this document, have been using made using the "GNU Image Manipulation Program" and are of the FVWM2 window manager, running the M4 preprocessor AnotherLevel.
As a final notice, I would like to say that as I am no longer at school anymore, my "n6tadam@users.purbeck. dorset.sch.uk" account is invalid, and I now have a new account (see below).
So until next time....happy linuxing!
 |
Send Your Comments | |
Any comments, suggestions, ideas, etc can be mailed to me by clicking the e-mail address link below:


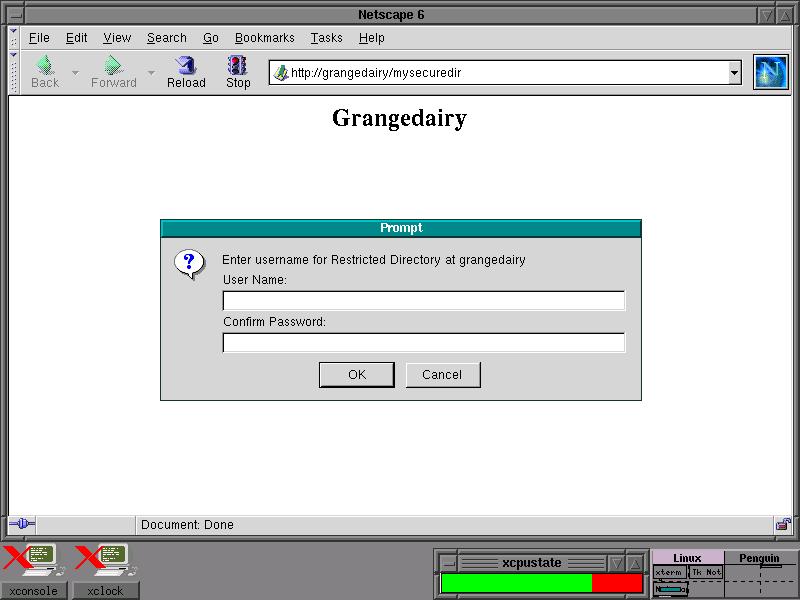{kind=link}
{kind=link}
{kind=link}